

Intels KI-Beschleuniger Gaudi 3 soll Nvidias H100 zerlegen
Intel stellt seine neue Generation KI-Beschleuniger aus der Schmiede Habana Labs vor: Die Gaudi-3-Beschleuniger sollen viel schneller als Nvidias H100 sein.

(Bild: Intel)
Intels Gaudi 3 soll Nvidias allgegenwärtigen H100-Beschleunigern Kunden abjagen und kommt außer als Open Accelerator Module (OAM) auch im Achterpack auf einem Universal Baseboard und als herkömmliche PCI-Express-Steckkarte mit bis zu 600 Watt Thermal Design Power (TDP). Die OAM-Version schluckt laut Intel bis zu 900 Watt beim KI-Training.
Große Rechnerverbünde bis hin zu Rechenzentren mit Tausenden von Beschleunigern soll Gaudi 3 wie schon der Vorgänger über standardkonforme Ethernet-Schnittstellen aufbauen. Intel betont hierbei besonders, dass man bei der Infrastruktur im Gegensatz zu Nvidias Angeboten die Auswahl zwischen verschiedenen Netzwerk-Anbietern hat.
Die Gaudi-3-Beschleuniger liefert Intel bereits in Musterstückzahlen aus, die Massenproduktion soll für die luftgekühlte OAM-Version im dritten Quartal 2024 starten, die flüssiggekühlte Option kommt ein Vierteljahr später. Anfangs werden die Chips in Geräten von Dell, HPE, Lenovo und Supermicro landen, im dritten Quartal erwartet Intel breitere Verfügbarkeit. Gaudi 3 wird in 5-Nanometer-Technik gefertigt, stammt also wie viele andere KI-Beschleuniger aus den Fertigungsstraßen von TSMC, denn Intel selbst hat keine Technik dieser Klasse im Angebot.
Gaudi-3-Doppeldecker

(Bild: Intel)
Gaudi 3 ist anders als Nvidias und AMDs Beschleuniger eine reine KI-Beschleunigerarchitektur und besteht, ähnlich wie Nvidias Blackwell, aus zwei identischen, ziemlich großen Chips. Genaue Details zum Aufbau gibt Intel nicht preis und so fällt der oberflächliche Vergleich mit den anderen Beschleunigern anhand der Rechenwerkszahlen besonders sinnfrei aus: 64 Tensor-Processor-Cores der fünften Generation und Matrix-Math-Engines (MME) lassen sich nur schwer mit den Dutzenden bis je nach Zählweise Tausenden Rechenwerken in H100, B200 oder AMDs Instinct MI300 vergleichen. Intel gibt allerdings an, jede MME führe bis zu 64.000 Operationen parallel durch.
Zur Vernetzung mit anderen Gaudi-3-Beschleunigern und den Wirtssystemen hat jeder Chip 24 Ethernet-Ports mit jeweils 200 Gbps (rechnerisch 25 Gigabyte pro Sekunde) und einen PCIe-5.0-x16-Anschluss.
Im Vergleich zum Vorgänger Gaudi 2 soll die neue Inkarnation massiv an Rechenleistung zugelegt haben. Intel spricht von insgesamt 1835 Billionen Gleitkomma-Operationen pro Sekunde (Teraflops, TFlops) bei FP8-Genauigkeit und nennt hierfür gegenüber Gaudi 2 Faktor 2. Sogar viermal schneller als der Vorgänger soll Gaudi 3 bei BF16-Genauigkeit sein. Hinzu kommen die doppelte Netzwerk- und 50 Prozent mehr Speichertransferrate. Sogar die auf 600 Watt begrenzte PCIe-Version soll 1835 TFlops schaffen, wenn Intel hier auch mit dem vorsichtigen Zusatz "Peak", also Spitze, operiert. Für Dauervolllast braucht es wohl noch ein paar Watt mehr.
Auch die 128 GByte HBM2e-Speicher mit 3,7 Terabyte pro Sekunde oder die 96 Megabyte SRAM-Cache mit immerhin 12,8 Terabyte pro Sekunde klingen daher nicht weltbewegend.
Schneller als Nvidia!?
Umso wichtiger ist, was hinten herauskommt. Hier gibt es bislang nur Zahlen, die der Hersteller Intel selbst ermittelt hat und die sehen den Gaudi 3 deutlich vor Nvidias H100 in Sachen Training von Large Language Models (LLM), beim Inferencing und auch bei der Energieeffizienz. So will Intel beim LLM Llama2-7B, also mit sieben Milliarden Parametern, 50 Prozent mehr Token pro Sekunde als Nvidias H100 schaffen. Mit dem größeren LLama2-13B sollen es sogar 70 Prozent mehr sein. Intel zieht als Vergleich von Nvidia mit Stand 28.3.2024 angegebene Leistungswerte unter https://developer.nvidia.com/deep-learning-performance-training-inference/training heran.

(Bild: Intel)
Beim Inferencing, also dem Ausführen bereits trainierter KI-Algorithmen, ist man etwas vorsichtiger und liegt bei den Llama2-7B- und -70B-Modellen laut eigener Aussage in der Regel um 10 bis 20 Prozent hinter Nvidias H200 [--] eine Neuauflage der H100 mit mehr und schnellerem Speicher. Beim weitaus größeren Falcon-LLM mit 180 Milliarden Parametern sieht man sich besonders bei längeren Output-Sequenzen um bis zu 280 Prozent schneller als Nvidias H200. Hier bezieht man sich auf Referenzwerte aus folgender Quelle: Performance of TensorRT-LLM — tensorrt_llm documentation (nvidia.github.io).
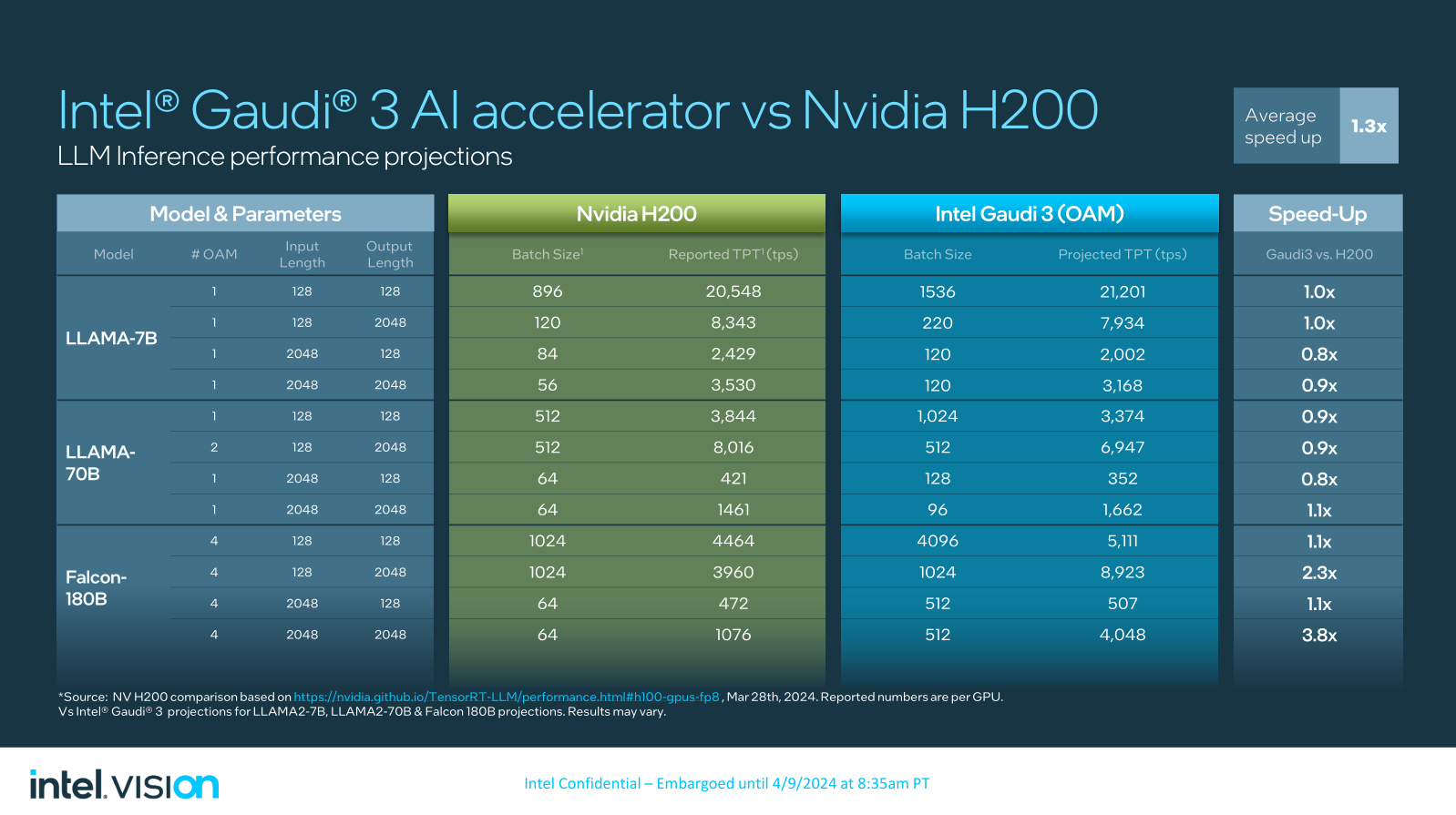
(Bild: Intel)
Auf die Frage, wie Gaudi 3 gegen die kürzlich angekündigten Nvidia-Blackwell-Chips abschneide, hielt sich Intel bedeckt und sagte, man wolle hier tatsächliche erbrachte Benchmark-Resultate wie etwa beim KI-Benchmark MLPerf abwarten. Selbst nennt man für Gaudi 3 allerdings "Projektionen" der Performance.
Gaudi ist eine Beschleunigerarchitektur für KI-Training und Inferencing. Die Technik wurde von den Habana Labs entwickelt. Das israelische Start-up hatte Intel im Jahre 2019 für knapp zwei Milliarden US-Dollar übernommen und ging damals noch von einem KI-Marktvolumen von 25 Milliarden US-Dollar bis 2024 aus. So viel setzt allein Nvidia momentan in nicht einmal einem halben Jahr mit KI-Chips um.
Auf Gaudi 3 soll schon 2025 die nächste Beschleunigergeneration mit dem Codenamen Falcon Shores folgen.


(csp)
