

Vertraulichkeit in der Cloud
Vernebelt
Daten sind vertraulich zu behandeln – auch in der Cloud. Das verlangt der Datenschutz und häufig auch das eigene Geschäftsmodell. Die Bandbreite der Mechanismen hierfür reicht von Datensparsamkeit bis zur homomorphen Verschlüsselung.
Vertraulichkeit und Cloud scheinen im Widerspruch zu stehen, schließlich gibt man die sensiblen Daten aus der Hand. Verschiedene Ansätze sollen die zwei Konzepte näher zusammenbringen. Diese Maßnahmen – vom Treuhandmodell über Pseudonymisierung bis zur homomorphen Verschlüsselung – versuchen, unterschiedliche Probleme zu lösen, und haben alle ihre Grenzen. Die Kunst besteht darin, aus der Risikoanalyse eine geeignete Kombination für den eigenen Anwendungsfall zu entwickeln. Die Notwendigkeit dafür beruht auf zwei aktuellen Trends:
1. Cloud-Nutzung nimmt quer durch fast alle Branchen und Sektoren stark zu.
2. Auch vertrauliche Daten landen zunehmend in der Cloud.
Die naheliegende Frage lautet daher: Wie kann Vertraulichkeit in der Cloud realisiert werden?
Cloud bezeichnet in diesem Beitrag einfach „somebody else’s computers“. Bei einem derartigen Angebot weiß man nicht mehr, wo die eigenen Daten liegen, und muss sich – zumindest aus betrieblichen Gründen – darum auch nicht mehr kümmern. Das impliziert, dass man nicht unbedingt weiß, wer auf denselben Systemen und Kommunikationsstrecken sonst noch unterwegs ist.
Worin besteht überhaupt der Antrieb, sensible Daten in die Cloud zu stellen? Hierauf gibt es mindestens drei Antworten.
Der erste Grund ist derselbe, aus dem Cloud-Nutzung an sich immer beliebter wird: Es ist bequem. Die Werbeversprechen (hohe Verfügbarkeit, einfaches Bezahlmodell …) verlangen zwar immer nach einem zweiten Blick. Doch ist einiges Wahre daran: Man lagert Aufwand aus, vermeintlich auch Komplexität sowie – gefühlt – Verantwortung.
Der zweite Grund bezieht sich auf die steigende Beliebtheit von Cloud-Angeboten bei den Anbietern: Für diese ergeben sich neben neuen Geschäftsmodellen (Everything as a Service) eine größere Macht über die Kunden(-daten) sowie nicht zuletzt zusätzliche Zweit- und Drittverwertungsmöglichkeiten in der neuen Big-Data-Welt.
Der dritte Grund lässt sich wahlweise als moralischer oder als pragmatischer begreifen: Bestimmte Daten sind in der Cloud bestimmter Betreiber in manchen Fällen tatsächlich besser aufgehoben als bei vielen Dateneigentümern zu Hause. Welche dies jeweils sind, hängt entscheidend vom Bedrohungsmodell ab.
Mehrere Bedrohungsmodelle
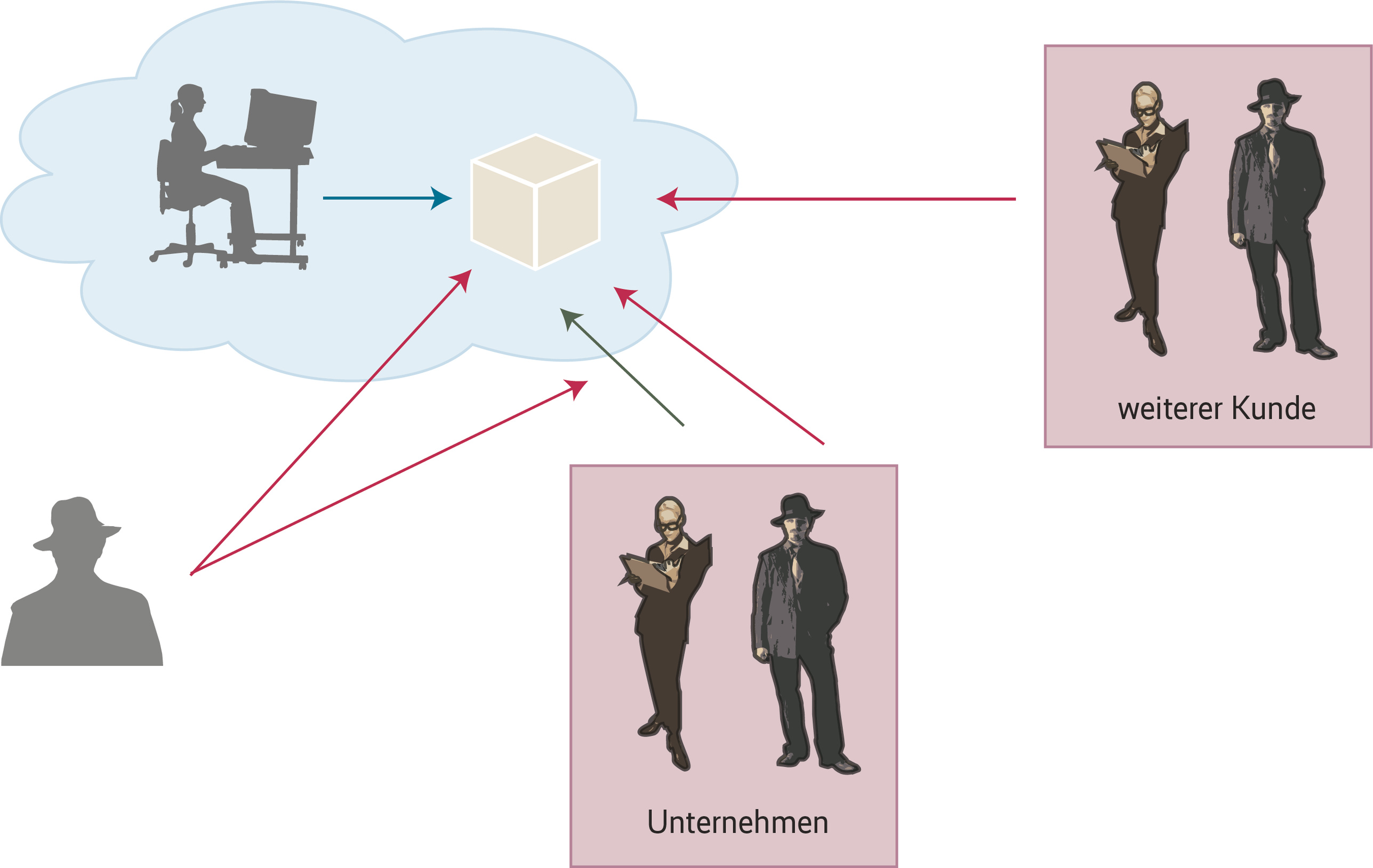
Die klassische Einteilung der Schutzziele der Security in Vertraulichkeit, Integrität und Verfügbarkeit ist sehr grob – sogar wenn manchmal halbherzig ergänzt durch Nebenziele wie Authentizität, Nichtabstreitbarkeit oder Nichtverkettbarkeit. Dass es sich lohnt, die Dimensionen des Problems genauer aufzuziehen, wird spätestens beim Thema Cloud deutlich. Beispiel Vertraulichkeit: Wer darf wann welche – und wessen – Daten nicht erhalten? Und warum? Es lassen sich mindestens fünf Fälle identifizieren. Bestimmte Daten dürfen nicht gelesen werden können von:
1. Dritten – anderen Internetnutzern, die keine Kunden des Cloud-Anbieters sind;
2. weiteren Kunden („Mandanten“) des Cloud-Anbieters;
3. anderen Mitarbeitern des Cloud-Nutzers;
4. bestimmten Mitarbeitern des Cloud-Anbieters;
5. allen Mitarbeitern des Cloud-Anbieters. Nicht einmal vom CTO.
Bei 1. bietet es sich im Sinne der in Security-Kreisen beliebten Worst-Case-Betrachtung an, von den üblichen Verdächtigen auszugehen: Mitbewerber, Cyberkriminelle, Hacktivisten. In der Praxis geht 1. fließend in 2. über, da die Hürden der Registrierung zumindest in der Public Cloud üblicherweise bewusst niedrig gehalten sind.
3. und 4. beschreiben das Standardproblem der Autorisierung – einmal auf Kunden-, einmal auf Anbieterseite – und sind insofern nicht auf Cloud beschränkt. Auf besondere Herausforderungen der dafür notwendigen Authentifizierung der Nutzer, Stichwort Federation, soll hier nicht eingegangen werden. Der Fokus dieses Artikels soll daher auf den zwei Fällen Lieblingsfeind und Cloud-Admin liegen.
Von Bären und Diensten
Wie bei jeglichem Risikomanagement kommt es bei der Security auch auf Wirtschaftlichkeit an. Wie viel Vertraulichkeit eine Information benötigt, hängt davon ab, welcher Schaden aus der Offenlegung entsteht – im Vergleich zum Aufwand, sich dagegen abzusichern. Der Hauptfeind ist derjenige Akteur, der diesen Maximalschaden am wahrscheinlichsten verursacht. Das können in der Praxis sowohl sogenannte Hungry Bears sein, die wahllos auf möglichst viel Beute aus sind, als auch Angry Bears, die es auf bestimmte Informationen abgesehen haben. Praktisch muss man sich gegen beide verteidigen, wobei die erwartete Verteilung über die Maßnahmen entscheidet.