

Moderne Textanalyse, Teil 1: Texte zerlegen und Zusammenhänge visualisieren
Ein Bild sagt mehr als tausend Artikel
Viele Informationen liegen nur als unstrukturierte Texte vor. Mit Modellen für natürliche Sprachverarbeitung, etwas Statistik und Maschinenlernen lassen sich Wissensschätze heben und verborgene Zusammenhänge aufspüren.
Nach wie vor ist Text die am weitesten verbreitete Kommunikationsform. Dank des Internets liegen heute riesige Mengen an Text in digitaler Form vor und lassen sich mit Rechnern automatisiert verarbeiten. Dieses Tutorial zeigt, wie man große Textmangen analysiert, strukturiert und klassifiziert.
Die Beispieltexte liefert der Heise-Newsticker. Sein Archiv hält sämtliche Artikel seit dem Beginn im Jahre 1996 vor – 186 142 bis Ende 2017. Viel zu viele, um sie ohne maschinelle Unterstützung alle selbst durchzulesen.
Das lädt natürlich zum Forschen ein. Mit der eingebauten Suchfunktion lässt sich leicht überprüfen, wann Heise beispielsweise zum ersten Mal über Bitcoin oder Ransomware berichtet hat. Deutlich schwieriger ist es aber, auch für regelmäßige Leser, Themen und Trends zu erkennen und Hypothesen wie „Es geht immer mehr um Datenschutz“ oder „Die CES spielt eine immer wichtigere Rolle“ mit Fakten zu bestätigen oder zu widerlegen.
Der Heise-Newsticker hat treue Leser, viele folgen der Plattform schon seit Jahren. So wie die Leser sich weiterentwickeln, entwickelt sich auch der Newsticker weiter. Eine umfassende Analyse der fast 190 000 Meldungen soll zeigen, wie sich die Artikel inhaltlich und sprachlich in den letzten Jahren verändert haben. Welche Themen erlebten einen Hype und sind dann schnell wieder in Vergessenheit geraten? Was sind die Dauerbrenner? Bestätigt sich das eingangs beschriebene Gefühl, dass Themen rund um den Datenschutz immer relevanter werden? Diese und weitere Fragen sind die Motivation für dieses dreiteilige Tutorial.
Fragen an den Newsticker
Beantwortet werden sie anhand der 186 142 Artikel, die zwischen 1996 und Ende 2017 auf dem Newsticker veröffentlicht wurden. Die Texte sind bereits per Webcrawler heruntergeladen und extrahiert, sie stehen zum Download unter ix.de/ix1803118 bereit (siehe Kasten „Download der Daten“).
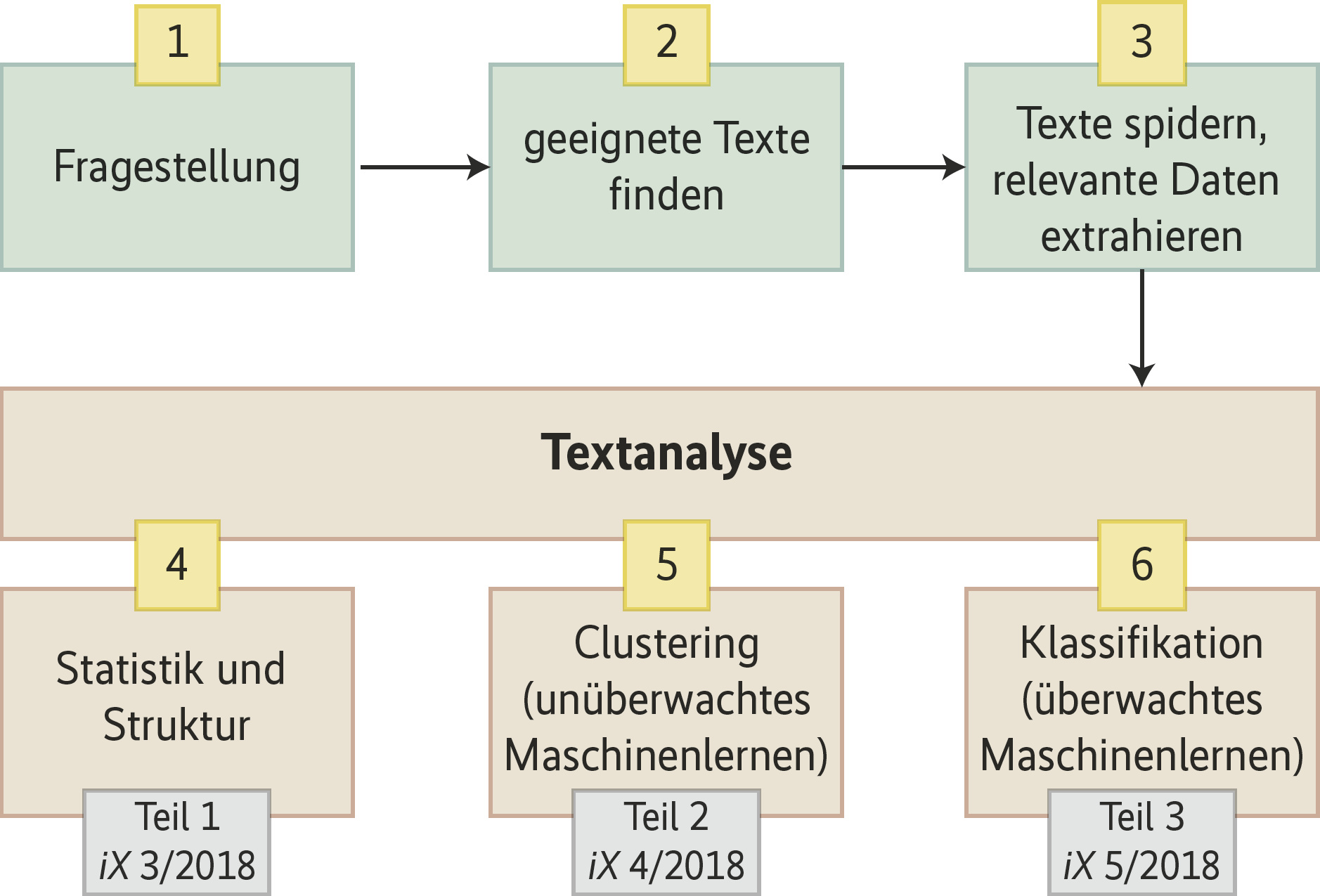
Der erste Teil des Tutorials erklärt, wie man aus den Texten Statistiken und Informationen zur Struktur der Texte ableitet und welche Werkzeuge dazu nötig sind. Im nächsten Heft werden die Texte mithilfe von unüberwachtem Machine Learning geclustert. Thema des dritten Teils dieses Tutorials ist eine Textklassifikation mithilfe von überwachtem Machine Learning.
Was ist so besonders an Text?
Sprache ist nicht nur das am weitesten verbreitete menschliche Kommunikationsmittel, sondern auch eines der ältesten. Die geschriebene Sprache – Text im eigentlichen Sinne – ist zwar deutlich neuer, gehorcht aber den gleichen Prinzipien wie gesprochene Sprache und ist damit inhärent unstrukturiert. Daher ist es für Computer sehr schwierig, den Sinn von Text zu erfassen – was bereits kleinen Kindern sehr leicht fällt. Wer häufiger mit Siri oder Alexa kämpft, kennt die Problematik: Die Wandlung von Sprache in Text funktioniert noch meistens sehr gut (erkennbar beispielsweise an korrekt verstandenen Eigennamen), die Interpretation misslingt jedoch immer wieder.
Andererseits liegen sehr viele Informationen lediglich in Form unstrukturierter Texte vor, was den Wunsch nach einer automatisierten Auswertung weckt, wie sie bei strukturierten Informationen beispielsweise in Data Warehouses selbstverständlich ist. Wem es gelingt, Text zu interpretieren, dem stehen viele Türen offen: Die persönlichen Assistenten sind eine Inkarnation der Fähigkeit, Texte zu interpretieren, Chatbots eine andere. Zudem lassen sich vielfältige Informationen aus gespeichertenen Texten extrahieren.
Der Grund, dass die maschinelle Interpretation von Text überhaupt funktioniert und sich gerade sehr stark verbreitet, sind die aktuellen konzeptionellen Fortschritte im Bereich der künstlichen Intelligenz, speziell beim Machine Learning. Wie man durch überwachte und unüberwachte maschinelle Lernverfahren neue Erkenntnisse aus großen Textmengen zieht, ist Schwerpunkt in Teil zwei und drei dieses Tutorials.
Speziell bei Deep Learning wurden in den letzten Jahren erhebliche Fortschritte erzielt. Deep Learning erfordert zwar enorme Rechenkapazitäten für den Lernvorgang selbst, glücklicherweise stehen aber für viele Aufgaben bereits mit Deep Learning trainierte Modelle zur Verfügung, die sich auch auf einem PC oder Notebook nutzen lassen.
Nicht jede Form von Machine Learning ist so rechenaufwendig wie das Training vielschichtiger neuronaler Netze, wie sie bei Deep Learning eingesetzt werden: Die von uns verwendeten Modelle lassen sich auf modernen PCs in kurzer Zeit trainieren. Dabei profitieren Entwickler von freien Bibliotheken, die mittels Deep Learning auf die Sprachanalyse trainiert wurden und sich in der Vorverarbeitung der Textdaten effizient nutzen lassen.