

Robuste Data-Science-Projekte mit Python und Luigi
Klempnerhandwerk
Mit Luigi lassen sich beliebig komplexe Datenpipelines in Python erstellen. Neben Fehlerbehandlung und Monitoring bietet das Framework eine Fülle an Modulen zur Einbindung gängiger Big-Data-Software.
Durch das stark wachsende Datenvolumen hat sich das Rollenverständnis von Data Scientists erweitert. Statt Modelle für einmalige Analysen zu erstellen, geht es immer häufiger darum, Prototypen in produktive Anwendungen zu überführen. Die Auswertungsmodelle sind dabei komplex und kombinieren oft unterschiedliche Software für Datenanalyse und Maschinenlernen wie Hive, Spark oder TensorFlow. Diese Prototypen müssen nun so umgesetzt werden, dass sie dem Anspruch an einen produktiven Applikationsbetrieb genügen.
Dazu gehört beispielsweise die Möglichkeit, die einzelnen Schritte der Analyse zu überwachen, Metriken über die Laufzeit bereitzustellen und verschiedene Teilaufgaben robust miteinander zu verknüpfen. Jede Teilaufgabe sollte zudem idempotent sein, sprich bei mehrmaliger Ausführung mit denselben Daten zum gleichen Ergebnis führen, um bei Fehlern oder wiederholtem Durchlauf konsistente Ergebnisse zu liefern. Das von Spotify entwickelte Open-Source-Framework Luigi hilft dabei, diesen Ansprüchen zu genügen, ohne dass Data Scientists gleich ein ganzes Repertoire neuer Technologien lernen müssen.
Die Werkzeuge des Klempners
Der Name Luigi ist eine Referenz auf die Klempnerbrüder Mario und Luigi aus dem Nintendo-Universum. Data-Science-Modelle sind oftmals aufeinander aufbauende Verfahren, die wie Rohrleitungen – Pipelines – miteinander verbunden sind. Die eigentliche Datenverarbeitung erfolgt dabei in aufeinanderfolgenden Aufgaben. Das Klempnern, gemeint ist das Zusammenstecken der einzelnen Teilaufgaben, erledigt ein Python-Skript.
Das Luigi-Framework nimmt einem dabei nicht nur das Workflow-Management ab, indem es sich um Abbrüche bei Fehlern kümmert, den Prozess an der richtigen Stelle wieder aufsetzt oder Benachrichtigungen verschickt. Vorgefertigte Module wie RangeDailyBase ermöglichen mit wenig Aufwand Aufrufe für definierte Zeiträume. Sie liefern damit nicht nur die Grundlagen für robuste periodische Trigger zur regelmäßigen Verarbeitung aktueller Daten, sondern auch für Backfilling-Mechanismen zur Verarbeitung der Daten aus beliebigen früheren Zeiträumen. Damit können sich Data Scientists auf die Implementierung der einzelnen Verarbeitungsschritte (Tasks) konzentrieren.
Die zentralen Konzepte von Luigi sind Targets, Tasks und Parameter. Targets sind häufig Dateien auf der Festplatte oder im HDFS (Hadoop Distributed Filesystem), es kann sich dabei aber auch um Einträge in einer Datenbank handeln. Sie fungieren als Checkpoints und stellen sicher, dass Tasks nicht mehrfach ausgeführt werden.
Für gewöhnlich muss man die Targets nicht selbst implementieren, denn neben LocalTarget (Datei im Dateisystem) und HDFSTarget stellt das Framework eine Fülle an Implementierungen für andere Big-Data-Software bereit. Dazu zählen zum Beispiel Apache Hive mit dem HiveTableTarget und dem HivePartitionTarget sowie Elasticsearch mit dem ElasticSearchTarget. Für den Zugriff auf Remote Files via SSH gibt es das RemoteTarget. Für einen Gesamtüberblick lohnt sich ein Blick in die sehr gute Dokumentation zu Luigi (siehe ix.de/ix1804108).
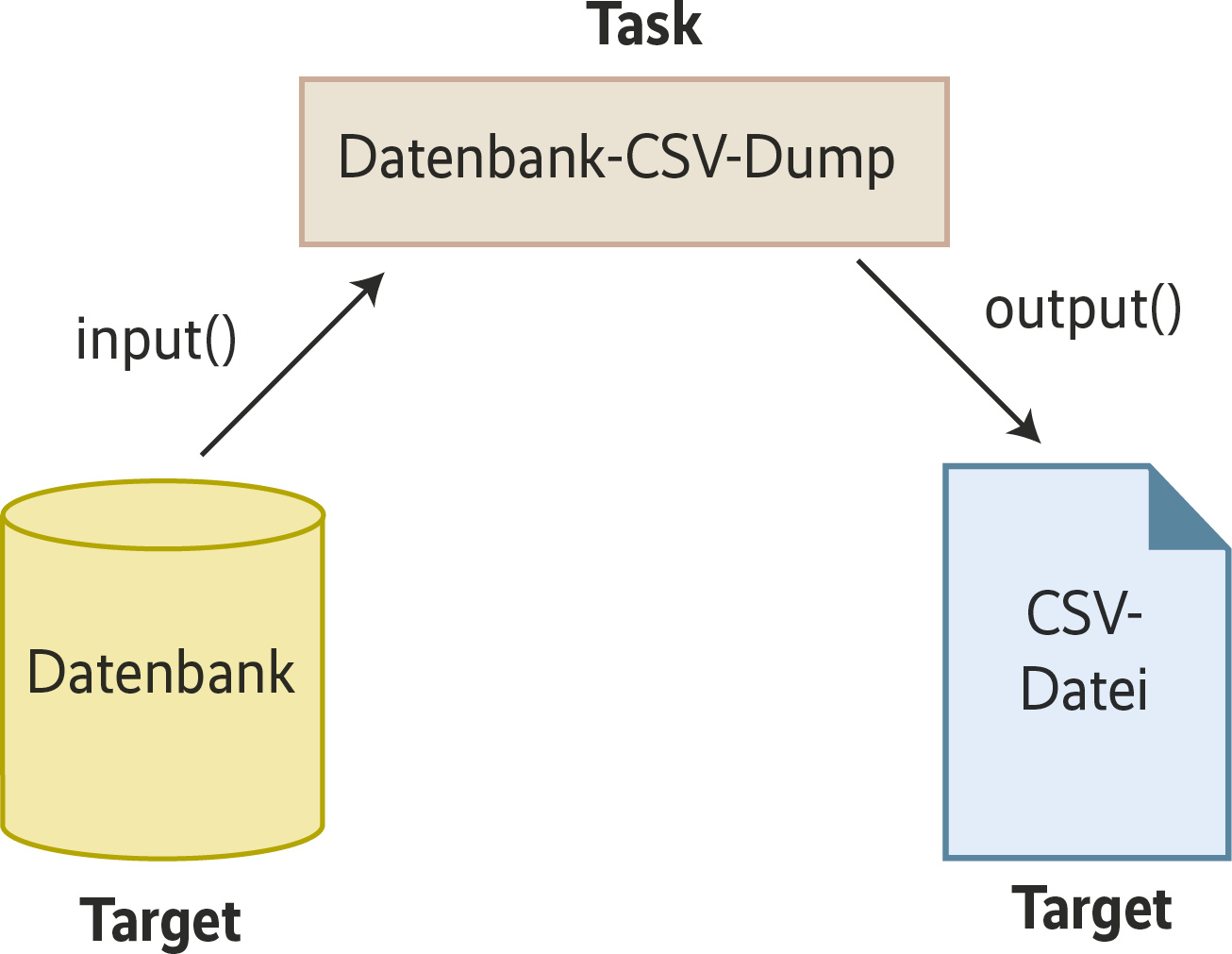
In den Tasks findet die eigentliche Verarbeitung statt. Sie konsumieren die zuvor beschriebenen Targets, verarbeiten die Daten und speichern das Ergebnis in einem neuen Target (Abbildung 1). Daneben werden in Tasks Abhängigkeiten zu anderen Tasks definiert, anhand derer Luigi die Pipeline sukzessive abarbeitet.
Listing 1: Aufbau eines Tasks
# test.py from luigi import Task, LocalTarget, Parameter class Beispiel(Task): parameter1 = Parameter(default="Test 1") parameter2 = Parameter(default="Test 2") def requires(self): return EinAndererTask(self.parameter2) def output(self): return LocalTarget("/tmp/test.checkpoint") def run(self): with self.output().open('w') as f: f.write(self.parameter1)
Tasks sind Klassen, die stets einen ähnlichen Aufbau haben. Bei der Implementierung überschreibt man die drei Methoden requires(), output() und run() der Basisklasse Task. Listing 1 zeigt an einem einfachen Beispiel, wie die Task-Klasse die Abhängigkeit von einem anderen Task abbildet und Daten als LocalTarget in eine Datei schreibt.
Um Abhängigkeiten zu anderen Tasks zu definieren, gibt die requires()-Methode einen Task oder eine Liste von Tasks zurück. Luigi prüft, ob diese Tasks bereits gelaufen sind; falls nicht, führt sie das Framework aus. Die Methode run() enthält den eigentlichen Code. Sie schreibt das Ergebnis der Verarbeitung in das in output() definierte Target. Zusätzlich besitzen Tasks die Methode input(), die als Wrapper um requires() die Output-Targets der Abhängigkeiten zurückliefert, sodass sich deren Ergebnisse einfach einlesen lassen.