

Moderne Textanalyse, Teil 3: Texte mit überwachtem Lernen klassifizieren
Apfel oder Birne?
Beim überwachten maschinellen Lernen wird ein Algorithmus darauf trainiert, Zusammenhänge in Daten zu erkennen und auf neue Daten anzuwenden. Damit lassen sich beispielsweise die Meldungen des Heise-Newstickers nachträglich mit passenden Schlagwörtern versehen.
Nachdem im ersten Teil des Tutorials (iX 3/2018) Strukturen und Zusammenhänge im Heise-Newsticker statistisch aufgedeckt und visualisiert wurden, konzentrierte sich der zweite Teil in iX 4/2018 auf die Nutzung von unüberwachtem Lernen zur inhaltlichen Gruppierung der Meldungen. Hier geht es nun um die Klassifikation von Texten in unterschiedliche Kategorien mithilfe von überwachtem maschinellen Lernen.
Abstrakt betrachtet zieht beim überwachten Lernen (Supervised Machine Learning) ein Algorithmus aus vorhandenen Daten (Trainingsmenge) Schlüsse, die er dann auf neue Daten anwendet. Eine sehr einfache Methode ist die (lineare) Extrapolation, die fast jedes Tabellenkalkulationsprogramm beherrscht: Durch eine zweidimensionale Punktemenge mit x- und y-Koordinaten wird eine Gerade gelegt.
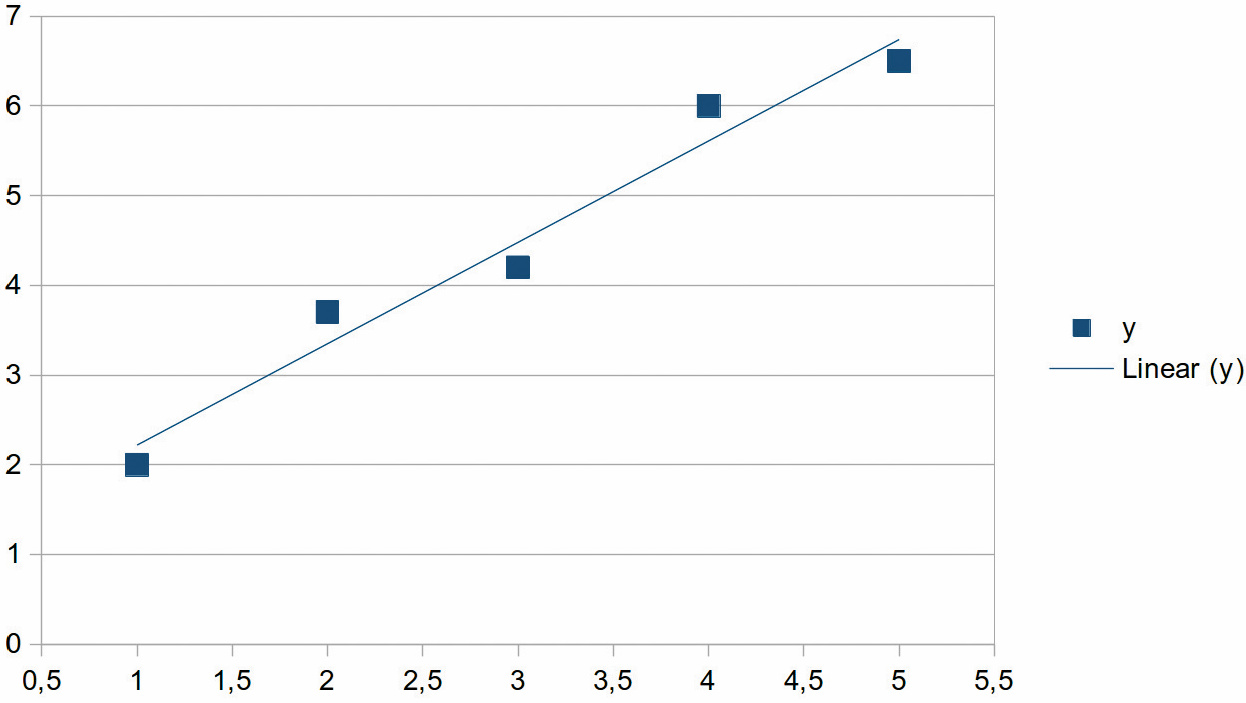
Eine solche Gerade in der Ebene lässt sich durch die Formel
y = mx + b
parametrisieren, man muss also die beiden Parameter m (Steigung der Geraden) und b (Verschiebung gegenüber dem Nullpunkt) bestimmen. Es gibt verschiedene Verfahren, um gute Parameterwerte zu finden. Am bekanntesten ist das Least-Square-Verfahren, bei dem die Summe der quadrierten Abstände der Punkte von der Geraden minimiert wird. Übertragen auf überwachtes Lernen bedeutet die Festlegung einer Geraden, dass der Algorithmus aus den vorhandenen Daten die Parameter der Geraden „gelernt“ hat. Er kann nun den y-Wert vorhersagen, wenn man ihm einen x-Wert vorgibt.
Dieses sehr einfache Beispiel zeigt bereits viele Eigenschaften, die im Folgenden eine wichtige Rolle spielen werden. So braucht man für überwachtes Lernen immer Trainingsdaten (die bereits vorhandenen x/y-Werte), das Verfahren ist nie exakt (die Gerade schneidet nicht alle Punkte), es sind immer Annahmen zu treffen (der Zusammenhang wird über eine Gerade modelliert) und man darf nie vergessen, den vermutlichen Fehler anzugeben (die Summe der quadrierten Abstände der Punkte von der Geraden).
Wie im zweiten Teil des Tutorials bereits ausgeführt, haben die Vektorräume für maschinelles Lernen viel mehr als zwei Dimensionen und die Punkte lassen sich auch nicht durch Geraden (beziehungsweise Hyperebenen) approximieren oder in unterschiedliche Klassen von Punkten trennen. Aber keine Sorge, diese Schwierigkeiten lassen sich heutzutage gut beherrschen und die Suche nach optimalen Parametern geht mit aktueller Hardware sehr schnell.
Bei Regressionsproblemen geht es um die Vorhersage kontinuierlicher Werte. Bei Texten möchte man fast immer diskrete Werte vorhersagen, die man dann als Kategorien bezeichnet. Solche Fragestellungen bezeichnet man als Klassifikationsprobleme. Davon gibt es unterschiedliche Arten. Die sogenannte Sentiment Detection beispielsweise klassifiziert Aussagen in Texten als positiv oder negativ – es gibt also nur zwei mögliche Ergebnisse. Man bezeichnet solche Fragestellungen daher als Single-Class-Probleme. Oft reicht diese Klassifikation allerdings nicht aus, denn nicht jeder Text enthält ein Sentiment. Man muss also eine weitere Kategorie („neutral“) einführen und spricht dann von einem Multi-Class-Problem.
Vom Text auf die Keywords schließen
Im Beispiel dieses Artikels geht es darum, aus dem Text der Newsticker-Artikel die dem Artikel zugeordneten Keywords vorherzusagen. Da es viele Schlagwörter gibt, ist auch dies ein Multi-Class-Problem. Erschwerend kommt hinzu, dass jedem Artikel nicht nur ein Keyword (ein „Label“) zugeordnet ist, sondern mehrere. Daher handelt es sich um ein Multi-Class-Multi-Label-Problem.