

Personenbezogene Daten DSGVO-konform maskieren
Maskenball
Die Datenschutz-Grundverordnung lässt keinen Zweifel daran: Unternehmen sollen personenbezogene Daten anonymisiert verarbeiten. Eine Möglichkeit dazu sind Maskierungen in Views. Apache Ranger und BlueTalon maskieren Daten in Big-Data-Umgebungen.
Bei der Verarbeitung personenbezogener Daten gelten strenge Regeln: Zum einen sieht die Datenschutz-Grundverordnung (DSGVO) das Prinzip der Datenminimierung vor. Zum anderen müssen die Daten von EU-Bürgern bei ihrer Verarbeitung so unkenntlich gemacht werden, dass keine Rückschlüsse auf konkrete Personen möglich sind.
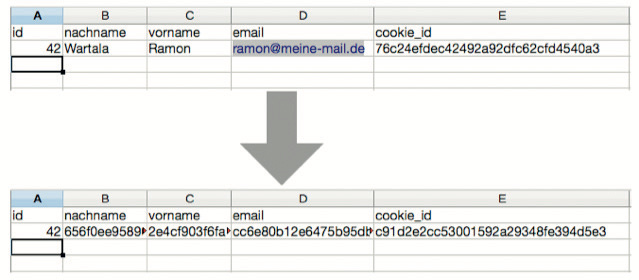
In den meisten Unternehmen werden Daten nicht zentral, sondern in vielen abteilungsspezifischen Datenbanken gespeichert und verwaltet. Selbst kleine Firmen haben heutzutage oft eine Vielzahl von Datenbanken. Das Problem dabei: Es existiert keine zentrale Stelle, an der man eine Anonymisierung oder Pseudonymisierung der Daten vornehmen kann. Stattdessen muss die Unkenntlichmachung in jedem einzelnen System entweder beim Import oder später beim konkreten Zugriff erfolgen.
Einige Firmen sind in den letzten Jahren dazu übergegangen, die Daten ihrer verschiedenen Systeme zentral an einem Ort – in einem Data Lake – zu speichern. Im Gegensatz zum klassischen Data Mart aus dem Data-Warehousing, der nur die für den speziellen Business Case nötigen Daten vorhält, speichert der Datensee alle Daten auch in Rohform ab. Das schafft neue Möglichkeiten, denn wer alle Daten permanent zur Verfügung hat, kann sich immer wieder neu entscheiden, welche er für die Realisierung eines bestimmten Anwendungsfalls heranzieht. Kostengünstige Systeme wie Hadoop in Verbindung mit Cloud-Speicherlösungen haben den Paradigmenwechsel begünstigt, indem sie die Vormachtstellung teurer und proprietärer Data-Warehouse-Systeme infrage gestellt haben.
Anders als das klassische Schema-on-Write ermöglicht Schema-on-Read eine deutliche Flexibilisierung der Datenhaltung. Diese Flexibilität lässt sich nutzen, um damit sehr einfach eine Zugriffsschicht zu etablieren, die ausschließlich unkenntlich gemachte Daten enthält.
Die technischen und organisatorischen Maßnahmen (TOM), die Unternehmen zum Schutz personenbezogener Daten implementieren, müssen sie gemäß DSGVO dokumentieren. Bei einem Data Lake fließen die Inhalte in der Regel durch automatisierte ETL- oder ELT-Prozesse in den Datenspeicher. Bis auf den Systemadministrator haben Menschen keinen Zugang zu den Daten.
Verschlüsselung und rollenbasierter Zugang
Auf Hadoop basierende Systeme haben in den letzten zehn Jahren eine Vielzahl an Sicherheitstechniken implementiert. Schon recht lange versteht sich das Framework mit Kerberos. Ein solcher „kerberisierter“ Hadoop-Cluster erlaubt den Zugang sowohl für Dienste als auch für menschliche Benutzer ausschließlich mit einem gültigen Token, und das nur nach erfolgreicher Authentifizierung mit Namen und Passwort oder auf der Basis einer speziellen Keytab-Datei. Der Systemadministrator kann hierfür einen eigenständigen Kerberos-Server aufsetzen oder den in Microsofts Active Directory eingebauten Wachhund nutzen.
Neben dem Zugriff auf das Dateisystem und die Hardwareressourcen eines Data Lake lassen sich mit Kerberos auch die Zugriffe auf Keys verwalten, die üblicherweise für die Verschlüsselung von Verzeichnissen im verteilten Dateisystem (HDFS) zum Einsatz kommen. Damit geschützte Verzeichnisse, sogenannte Encrypted Zones (siehe ix.de/ix1807112), lassen sich nicht mehr auslesen und bieten auch im Cloud-basierten Umfeld die nötige Sicherheit vor ungewollten Zugriffen.
(Big-Data-)Datenbanken wie HBase, Hive, Impala oder Analysesysteme wie Spark und Storm können transparent auf Daten innerhalb einer auf diese Art und Weise abgesicherten Umgebung zugreifen. Darüber hinaus lassen sich abhängig vom verwendeten System noch weitere Rechte vergeben. Um die Sichtbarkeit der Daten auf Datenbank-, Tabellen- und Spaltenebene zu steuern, bietet Clouderas Hadoop-Distribution zum Beispiel einen Dienst mit dem Namen Sentry. Der „Schildwächter“ erlaubt das Management von Rollen, mit denen der Administrator den Zugriff nutzerbasiert steuert.