

Deep-Learning-Modelle mit Amazons SageMaker
Neue Weisheiten
Dass „intelligente“ Programme aus Daten lernen, ist längst der akademischen Nische entwachsen. Wer Modelle für das maschinelle Lernen entwickeln, trainieren und nutzen will, findet Unterstützung bei Amazons Onlinedienst SageMaker.
Mit SageMaker bietet Amazon Web Services (AWS) einen neuen Service rund um die Erstellung von Machine-Learning-Modellen an (zur Funktionsweise dieses Amazon-Dienstes siehe ix.de/ix1809058). SageMaker soll nicht nur das Modelltraining, sondern auch das Tuning und insbesondere das Deployment stark vereinfachen. Dieser Artikel untersucht, wie der Dienst aufgebaut ist und wie er sich mit herkömmlichen Tools und Prozessen vergleichen lässt.
Wer Machine Learning (ML) sinnvoll in einem Unternehmen mit etablierten Prozessen einsetzen will, benötigt diverse Fähigkeiten und Kenntnisse. Aus vielen Artikeln über Data Science und Machine Learning ergibt sich der Eindruck, dass die Auswahl und das Tuning eines Algorithmus im Vordergrund stehen. In den meisten Projekten sind diese Schritte – gemessen am Gesamtaufwand – aber für einen erfolgreichen ML-Service der deutlich kleinere Teil.
Dies betrifft nicht nur organisatorische Fragen, etwa die Anwenderakzeptanz, sondern gilt auch für eine Vielzahl technischer Aspekte. Auf letztere konzentriert sich dieser Artikel. Für einen erfolgreichen Einsatz benötigt man ein System, das robust genug ist, im Rahmen von Geschäftsprozessen ohne ständige Ausfälle oder manuelle Nachjustierungen zu laufen. Hierfür steht plötzlich nicht mehr nur die Modellqualität im Fokus, sondern auch Themen wie API-Design, Skalierbarkeit und Monitoring.
Machine Learning produktiv nutzen
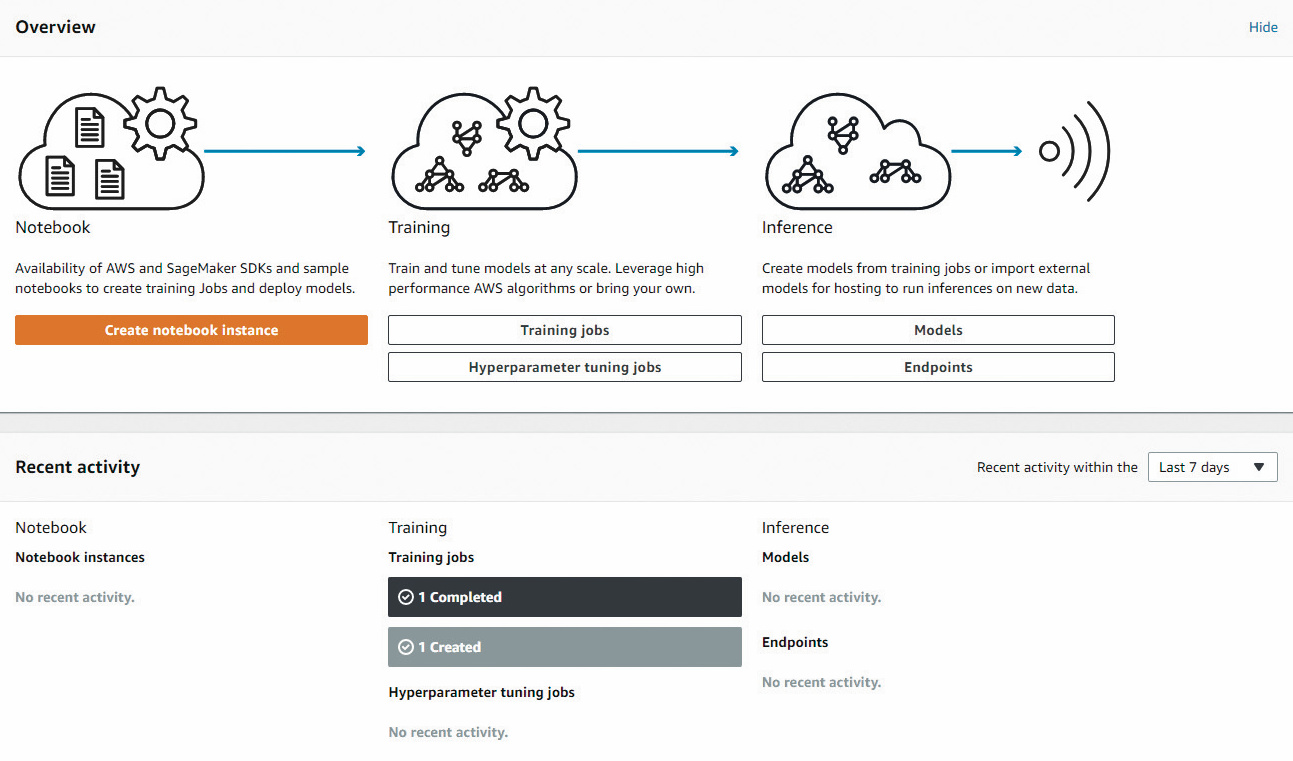
Google weist beispielsweise in dem Paper „Hidden Technical Debt in Machine Learning Systems“ darauf hin, dass der eigentliche ML-Code in diesen Systemen oftmals den kleinsten Anteil hat und die tatsächliche Arbeit erst mit dem Betrieb dieser Systeme beginnt [1]. Genau hier versucht SageMaker, Unterstützung zu leisten und die Arbeit des Modellerstellers leichter in eine produktive Nutzung zu überführen. Amazon steht mit dieser Art von Diensten nicht allein. Cloudera bietet beispielsweise mit der Data Science Workbench ein ähnliches Produkt an. Allerdings hat SageMaker momentan einen größeren Funktionsumfang. Auch Google und Microsoft haben im Rahmen ihrer Cloud-Angebote ähnliche Produkte. SageMaker stellt primär drei Dienste zur Verfügung:
– gehostete Jupyter Notebooks,
– Training und Ausführung proprietärer ML-Algorithmen,
– Bereitstellung trainierter Modelle als API-Endpoint.
Für jeden Dienst gibt es leicht unterschiedliche Preise. In Dublin kostet eine Notebook-Instanz je nach angeforderter Hardware zwischen 0,05 und 4,97 US-Dollar pro Stunde. Für das Training steht ein größeres Set an möglicher Hardwareausstattung zur Verfügung, mit einer Preisspanne von 0,15 bis 7,19 US-Dollar pro Stunde. Will man GPU-Instanzen verwenden, verlangt Amazon für beide Services bis zu 37 US-Dollar pro Stunde. Auch das Betreiben eines Modell-Endpoint kostet pro Stunde und nicht etwa pro Aufruf (Details siehe unter ix.de/ix1809058).
Im Folgenden geht es um diese drei Dienste und ihre Integration in bestehende Datentransformationsprozesse mithilfe von Apache Spark.
Notebook-Software für Prototyping
In den letzten Jahren hat sich Notebook-Software als elementarer Bestandteil im Arbeitsprozess von Data Scientists durchgesetzt. Die Kombination aus interaktiver Shell, vernünftigen Editorfunktionen, Visualisierung und Dokumentation macht Notebooks zu einem idealen Werkzeug für das schnelle Ausprobieren und Prototyping.
SageMaker nutzt als Einstiegspunkt für die Datenaufbereitung und Modellerstellung die im Python-Umfeld beliebten Jupyter Notebooks. Der Nutzer kann nach wenigen Konfigurationsschritten eine Notebook-Instanz starten. Im Wesentlichen sind nur ein S3-Bucket, ein Berechtigungsprofil und die Hardwareausstattung der Instanz anzugeben. Über den S3-Bucket als Dateisystem kann der Nutzer Daten für das Notebook und für die proprietären Modelle verfügbar machen und später wieder dort ablegen.
Jede Instanz enthält verschiedene Notebooks mit Beispielen zu den unterschiedlichen Algorithmen sowie zur Nutzung von SageMaker- und AWS-Funktionen. Spezielle Kernels – zum Beispiel für Python, Apache Spark oder TensorFlow – sind bereits installiert. Der über Anaconda eingerichtete Python3-Kernel beinhaltet eine Vielzahl an vorinstallierten Paketen, sodass man im Rahmen der SageMaker-Nutzung für diesen Artikel keine Pakete für Datenaufbereitung, Visualisierung oder Modelltraining nachinstallieren muss. Beispielsweise ist der TensorFlow-Kernel so eingerichtet, dass viel genutzte Pakete bereits mitinstalliert sind, die für andere ML-Frameworks typischerweise nicht benötigt werden. Um die Scala-Schnittstelle von Apache Spark nutzen zu können, muss man den von IBM entwickelten Jupyter Kernel Apache Toree verwenden.