
{kind=link}
RDS-Tutorial, Teil 1: RDS einrichten, konfigurieren und testen
Erleichtert
Dieses zweiteilige Tutorial hilft bei der Einrichtung und Inbetriebnahme des Amazon Relational Database Service. Teil 1 blickt zudem hinter die Kulissen von Datenmodell, Speicherverwaltung und Preisgestaltung.
Workload, Daten- und Speichermodell und Kriterien wie zu erwartender Durchsatz und Abfragekomplexität im vorgesehenen Einsatz geben die zu wählende Datenbankarchitektur mehr oder weniger vor. Braucht man Transaktionen, kommt man am ACID-Prinzip (siehe Kasten „ACID, BASE und CAP-Theorem“) und daher an einer relationalen Datenbank kaum vorbei – etwa im klassischen Einsatzbereich OLTP. Ist zudem das Datenbankschema komplex, erfordert das Datenmodell Fremdschlüsselbeziehungen und sind die zu erwartenden I/O-Anforderungen nicht exorbitant, wird man daher auch in der Cloud eine relationale Datenbank verwenden. Hier hat der Nutzer die Wahl zwischen DIY auf Basis virtueller Maschinen und einem vom Cloud-Anbieter verwalteten Datenbankservice. Letzterer bietet als verwalteter Service den entscheidenden Vorteil, dass man sich nicht selbst mit der OS- und Datenbankinstallation sowie mit dem Einspielen von Updates und Patches beschäftigen muss. Auch um Backups und Hochverfügbarkeit kümmert sich in diesem Fall der Hoster, wie Abbildung 1 zeigt.
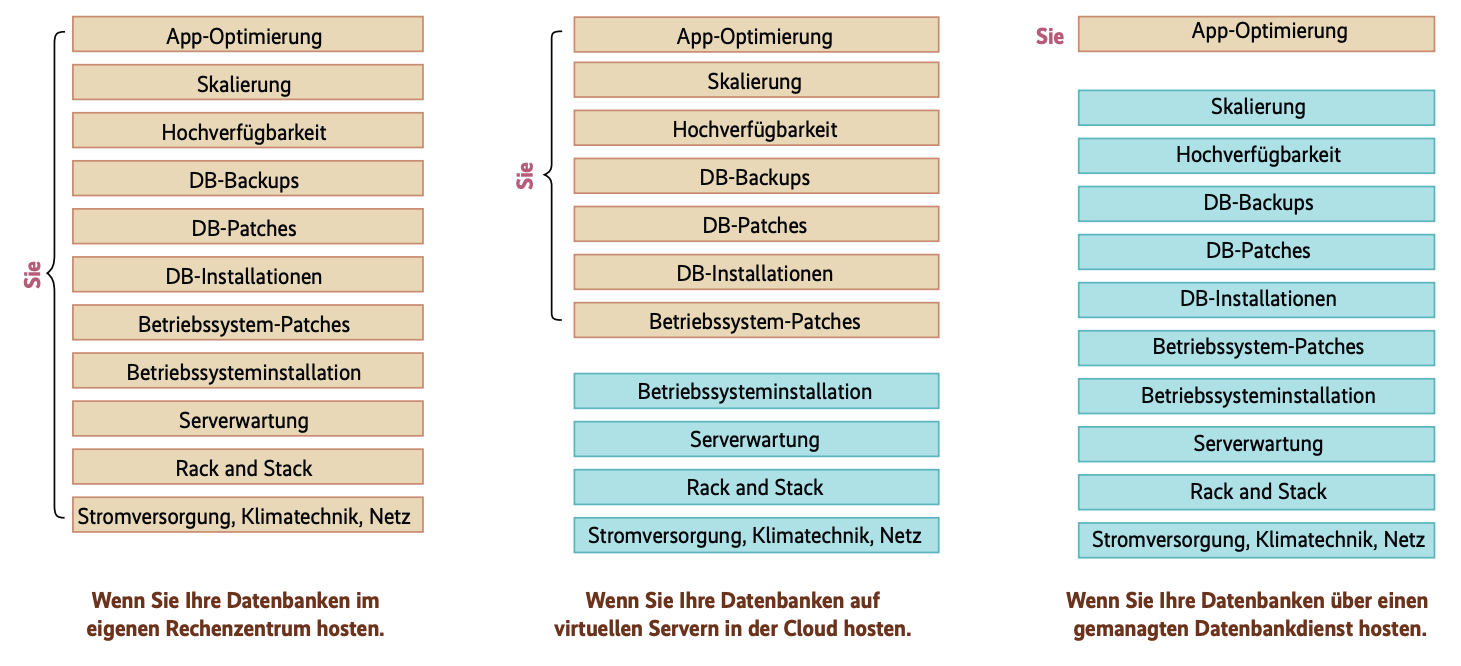{kind=link}
Virtuelle Datenbankserver in der Cloud
Amazon RDS ist ein von AWS verwalteter Dienst zum Betrieb relationaler Datenbanken in der Cloud oder genauer gesagt: auf Basis virtueller Server in der Cloud. Da sie vom Hoster verwaltet werden, muss der Administrator selbst kein Betriebssystem und keine Datenbank-Engine installieren, hat diesbezüglich jedoch auch keine uneingeschränkten Auswahlmöglichkeiten.