

Was In-Memory-Datenbanken leisten
Im Gedächtnis
RAM als Datenspeicher – auf dieses Prinzip setzen In-Memory-Datenbanksysteme (IMDB). Sie nutzen den Hauptspeicher eines Servers als beschleunigenden Cache und sind damit deutlich performanter als herkömmliche Datenbanken. Besonders im Big-Data-Bereich, wo große Datenmengen analytisch verarbeitet werden müssen, können IMDBs ihre Vorteile ausspielen.
Die Einsatzszenarien für IMDBs sind heutzutage so zahlreich, dass von einem Nischenprodukt keine Rede mehr sein kann. Neben Systemen, die konsequent auf die In-Memory-Technologie setzen, gibt es von fast allen großen Datenbankanbietern – von Oracle bis IBM – ein In-Memory-Add-on für ihre sonst diskorientierten Systeme. Bei den verschiedenen Angeboten ist der In-Memory-Ansatz also unterschiedlich stark ausgeprägt – mit den im Folgenden beschriebenen Vor- und Nachteilen.
Die Nachfrage nach einer IMDB entsteht immer aus der Praxis, vor allem dann, wenn Unternehmen ihre Geschäftsentscheidungen mehr und mehr anhand von Daten und deren Analyse treffen. Zwar gibt es IMDBs auch für transaktionale Systeme, die die Daten dort verarbeiten, wo sie entstehen, zum Beispiel auf Websites. Dafür sind jedoch NewSQL-Lösungen wie MongoDB oder Couchbase zumeist die bessere Wahl. Statt mit klassischen Tabellenzeilen und -relationen arbeiten diese mit anderen Strukturen wie Key-Value-Stores. Solche Systeme ermöglichen eine besonders performante und skalierbare Verarbeitung einzelner Objekte.
Für analytische Anwendungsfälle ist jedoch die Abspeicherung in Relationen vorteilhafter. Denn für die Auswertung werden große Datenmengen miteinander verknüpft, etwa mittels Joins, Aggregationen und analytischen Funktionen. Das macht die IMDB besonders für diese Szenarien interessant – als Teil eines Data Warehouse und einer Business-Intelligence-Strategie.
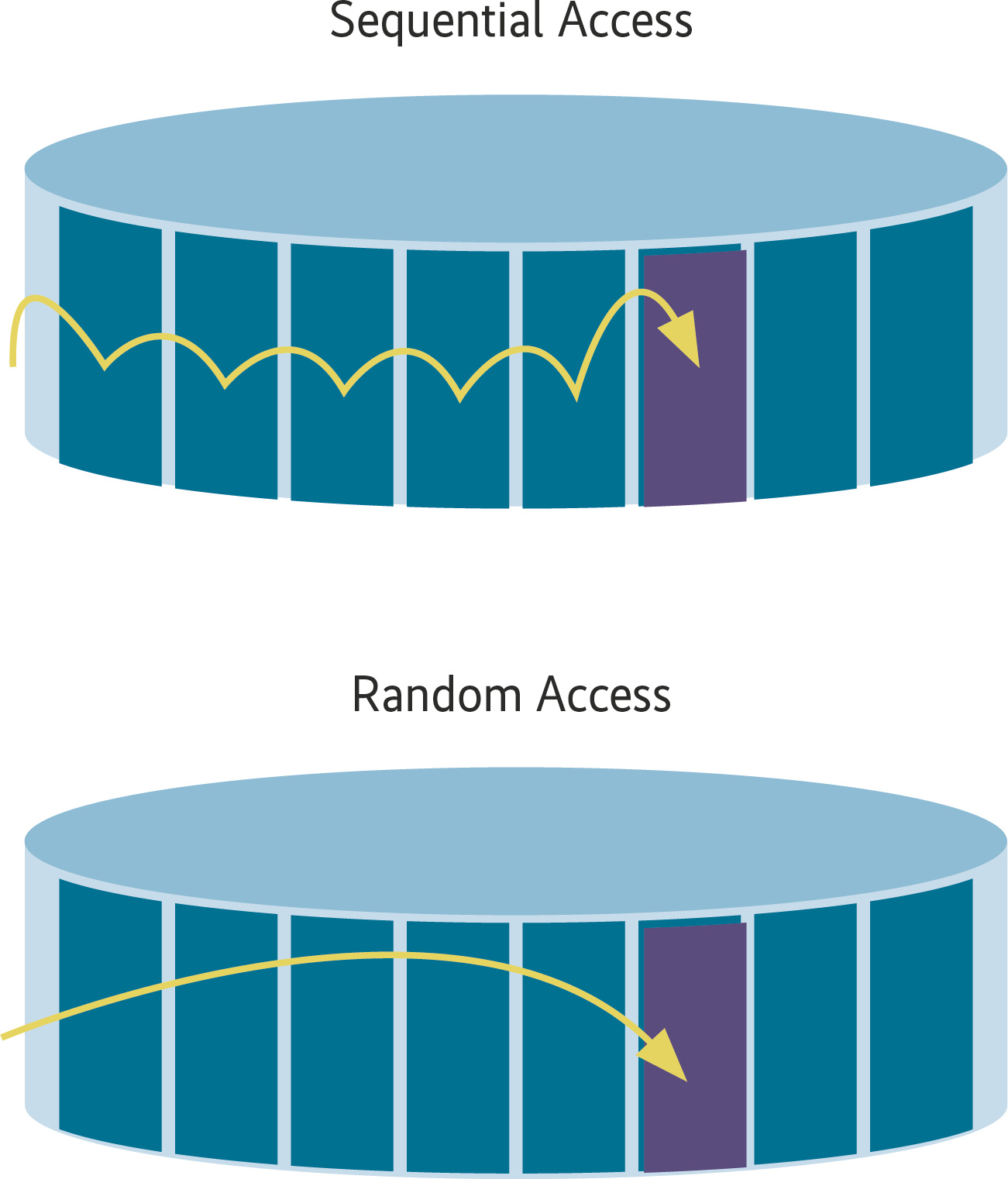
Die In-Memory-Technologie bearbeitet Querys deutlich schneller als herkömmliche relationale Datenbanksysteme, weil sie den Hauptspeicher als beschleunigenden Cache nutzen kann. Klassische, relationale Datenbanksysteme müssen aufgrund des Flaschenhalses Diskzugriff immer große Blöcke von den Festplatten einlesen und verarbeiten diese dann nacheinander. Das ist in etwa so, als müsste ein Telefonbuch mit Tausenden Seiten nach dem Vornamen anstatt nach dem Nachnamen umsortiert werden und dabei dürfte immer nur eine Seite gleichzeitig geöffnet sein. Es könnte dann immer nur die eine Seite lokal sortiert und mit den beiden Nachbarseiten verglichen werden. Ein enormer Overhead entsteht, der die Verarbeitung extrem verlangsamt. Im Gegensatz hierzu ermöglichen IMDBs Random Access auf die Daten. Jede Speicherzeile kann dabei direkt über ihre Speicheradresse angesprochen werden, und zwar rasend schnell. Bei dem Beispiel des Telefonbuchs könnten alle Seiten offen liegen und auf jedes Element kann direkt zugegriffen werden. Insgesamt wäre die Umsortierung um viele Faktoren schneller.
Höher, schneller, weiter ...
In beinahe allen Industriezweigen sind datengetriebene Prozesse mittlerweile die Basis für Businessentscheidungen. Dabei geht es keineswegs nur um traditionelles Data Warehousing und das Erstellen von Reports mithilfe von BI-Tools. Der Trend geht immer mehr Richtung Near-Real-Time-Entscheidungen im ganzen Unternehmen, bei denen es auf eine möglichst niedrige Latenz ankommt. Je höher die Geschwindigkeit ist, mit der komplexe Anfragen ausgewertet werden, desto zügiger können Entscheider reagieren und umso mehr Analysen lassen sich durchführen. Bei Anwendungen, die auf automatisierten Entscheidungsalgorithmen beruhen, wie etwa Dynamic Pricing oder IoT-basierte Laufzeitoptimierungen von Industrieanlagen, ist der hohe Durchsatz beim Analysieren ein wichtiger Wettbewerbsfaktor. Gerade in den Bereichen Industrie 4.0 (Predictive Maintenance), IoT (autonomes Fahren) und den neuen Geschäftsfeldern im Fintech-Umfeld kommt man ohne leistungsstarke Datenanalysen nicht mehr aus.