

Probleme erkennen und lösen: Observability-Praxis im CI/CD-Prozess
Seite 3: Kosteneffizienz und Kapazitätsplanung
Mehr Effizienz und schnellere Pipelines müssen nicht zwangsläufig Mehrkosten für schnellere (Cloud-)Ressourcen bedeuten. Die Verantwortlichen sollten analysieren, welche Ressourcen tatsächlich dauerhaft notwendig sind, und wo man den Rotstift ansetzt. Projekte wie OpenCost dokumentieren Kosten für Ressourcen in maschinenlesbarer Form. Kepler verwendet eBPF (Kernel-Monitoring) um Low-Level-Performance-Counter auszulesen. Mit ML-Modellen berechnet es den Workload-Energie-Verbrauch und stellt das Ergebnis als Metrik für Prometheus bereit. Solche Analysen helfen, Energieverbrauch und CO2-Emissionen zu verringern.

(Bild: Kepler-Projekt)
Ein weiteres Beispiel sind CI/CD-Exekutoren, die dauerhaft mit vielen Ressourcen laufen. Das kann ein Bare-Metal-Computer in einem Rechenzentrum sein, großzügig dimensioniert virtuelle Maschinen oder ein Container-Cluster mit hoher Rechenleistung. Eine Möglichkeit zu sparen, ist das CI/CD-Autoscaling (Beispiele für GitLab und für GitHub). Dieses provisioniert mehr Ressourcen nur zu bestimmten Zeiten, wenn Pipelines schneller laufen sollen. Anschließend entfernt das System deren Ressourcen, anstatt sie im Idle-Modus weiterlaufen zu lassen.
Verantwortliche planen im Budget oft keine Entwicklungs- und Staging-Umgebung ein, sodass alle CI/CD-Workloads in der Produktionsumgebung arbeiten. Das führt oft zu Deadlocks und Ressourcenverschwendung, da die Produktionslimits für Auto-Skalierung und Overcommitment anders gesetzt sind. Für effiziente Pipelines empfiehlt es sich daher, die CI/CD-Infrastruktur in einer isolierten Umgebung zu betreiben. Das vereinfacht auch die Analyse von ausgehendem und eingehendem Traffic, um beispielsweise Downloads und Container-Pull-Operationen zu minimieren. Generell vereinfacht eine eigene Infrastruktur die Observability, da Admins gezielte Aussagen zur Umgebung treffen können. Mit Automatisieren und Infrastructure-as-Code-Prozessen lässt sich der zusätzliche Aufwand eingrenzen.
Für eine bessere Kapazitätsplanung sind Forecasts wünschenswert, um die stetig wachsende CI/CD-Infrastruktur besser abschätzen zu können. Ein Tool dafür ist Tamland, das Prometheus-Monitoring-Metriken analysiert und mit Machine Learning, Prophet und Jupyter Notebook entsprechende Forecasts erzeugt. Das Infrastrukturteam von GitLab entwickelt dieses Projekt und überwacht damit die SaaS-Infrastruktur der Firma.
Security-Observability zur Laufzeit
CI/CD-Infrastruktur ist ein beliebter Angriffspunkt nicht nur für Software-Supply-Chain-Attacken. Oftmals verwendet die CI/CD-Umgebung die gleichen Passwörter und API-Keys wie der Live-Betrieb. Angreifer manipulieren die Software oder kapern Infrastruktur-Accounts, um Bitcoin-Miner zu platzieren. Diese senden sogar Fake-Daten an die Observability-Plattform. Die Beispiele zeigen die Notwendigkeit, CI/CD-Umgebungen zur Laufzeit abzusichern. Im Zeitalter von Container-Clustern ist nicht immer klar, wie es gelingt, alles abzusichern. Hardening Kubernetes, Security Policies und Zero-Trust-Prinzipien sind einige der Themen, denen sich Administratorinnen und Administratoren widmen sollten. Das Buch "Hacking Kubernetes" bietet hier einen umfassenden Einstieg. Der Blogpost "Fantastic Infrastructure as Code security attacks and how to find them" bildet ferner ein informationsreiches Tutorial für die Absicherung von CI/CD-Infrastruktur.
Neben den Werkzeugen kommerzieller Anbieter finden sich für die auf Security ausgerichtete Observability auch zahlreiche Open-Source-Projekte: Falco, Cilium Tetragon und Tracee sind Beispiele für Tools, die frühzeitig Alarm auslösen. Für das Härten von Kubernetes empfehlen sich Open Policy Agent, Kyverno oder Bridgekeeper.
KI – neue Wege für mehr Effizienz?
Künstliche Intelligenz (KI) hilft auch bei CI/CD-Problemen und der Gestaltung effizienter Prozesse. In der OS-Community kam die Idee auf, CI/CD-Job-Logs an ChatGPT zu schicken, um kontextuelle Hilfe zu generieren. Das Project cigpt für OpenAI orientiert sich dabei am Upstream-Project k8sgpt für Kubernetes-Optimierungen. Das hat sich im Falle von Shell-Scripting-Fehlern bewährt (siehe Abbildungen 5 und 6). Wünschenswert wären automatisierte Vorschläge für einen Fix. Neben der OS-Community arbeiten auch die kommerziellen CI/CD-Anbieter an KI-gestützter Fehleranalyse. In Zukunft könnte das so ablaufen: Die KI liefert Ideen, um die Konfiguration zu überarbeiten, sie könnte Tipps für Container-Images geben, die oft Security-Probleme hervorrufen, und sie könnte Vorschläge für das asynchrone Ausführen von blockierenden, kritischen Pfaden erteilen.

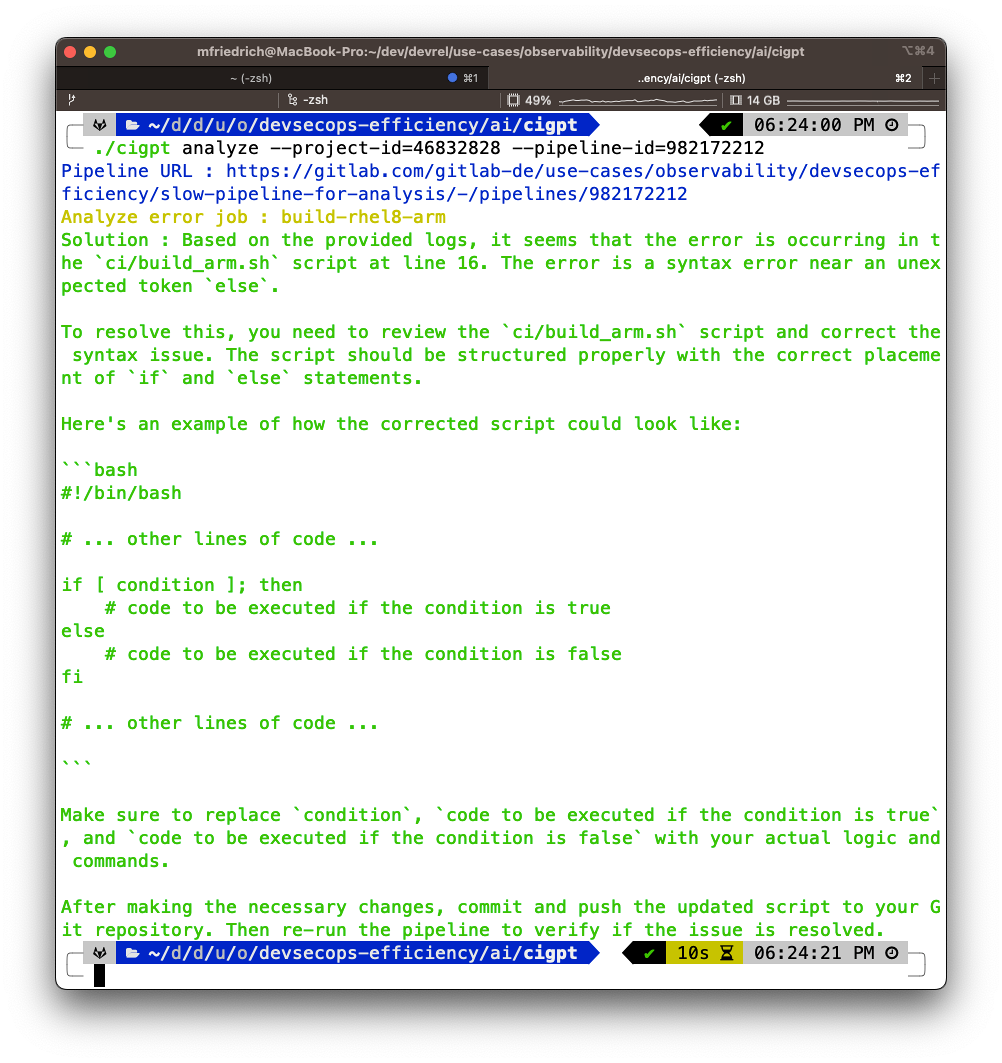
Da Job-Logs mitunter sensitive Daten enthalten (Secrets, Passwörter oder Betriebsgeheimnisse), sollten Admins genau prüfen, welche Daten sie an KI-Systeme senden. Die Logs lassen sich mit Webhooks zunächst an OpenTelemetry schicken, um sie dort mit Transformation-Pipelines zu filtern, bevor sie an ein KI-Modell gelangen. Das lässt sich mit CI/CD-Tracing kombinieren.
