

Prometheus-Tutorial, Teil 2: Installation im Cluster
Warnleuchte
Prometheus soll komplexe Systeme überwachen. Seine Installation selbst sollte ebenfalls gut geplant sein.
Monitoring großer, skalierbarer Umgebungen stellt andere Anforderungen als das konventioneller Setups – darüber herrscht nach dem ersten Teil dieses Tutorials Klarheit. Die Prometheus-Entwickler haben ihr Werkzeug deshalb speziell für die Überwachung großer Umgebungen sowie für Trending konzipiert.
Klar sollte allerdings sein: Monitoringsoftware wie Prometheus für den Einsatz in komplexen Setups geht selbst mit einiger Komplexität einher. Wer sich frühzeitig Gedanken über die Struktur und Architektur macht, erspart sich viel Ärger zu einem späteren Zeitpunkt, etwa wenn das Skalieren des Monitoringsystems selbst ansteht. In diesem zweiten Teil des Tutorials zeigt iX, wie sich ein Cluster für die Überwachung durch Prometheus einrichten lässt. Welche Komponenten werden benötigt, wie gelangt die Software auf die Knoten und welche Hilfswerkzeuge stehen zur Verfügung? Welche Hardware ist am Anfang Voraussetzung und wie lässt sich später skalieren?
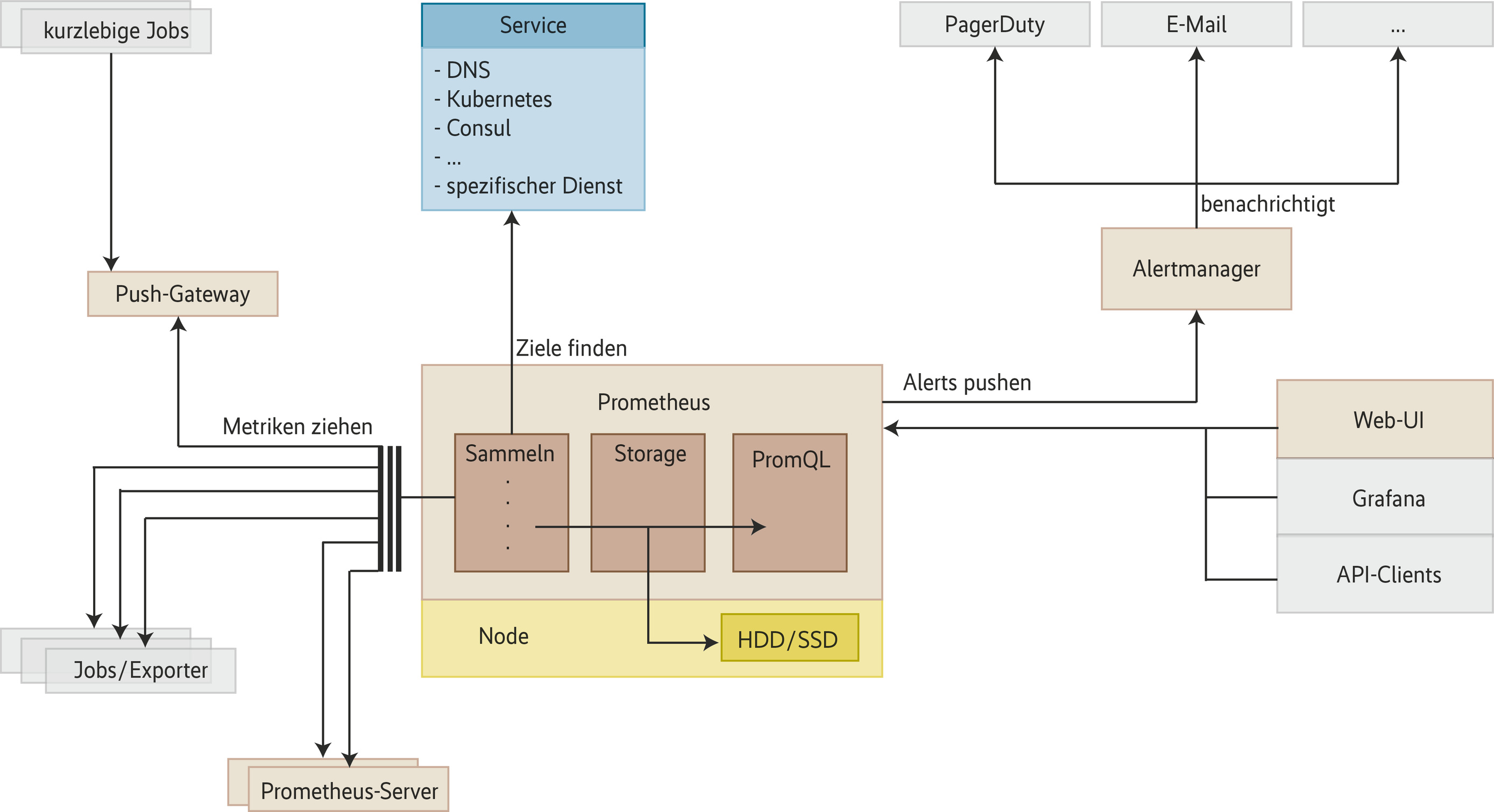
Ein Prometheus-Setup besteht aus mehreren Komponenten – auf der Serverseite Prometheus selbst sowie der Alertmanager und im Normalfall wenigstens Grafana, um die Metrikdaten zu visualisieren. In aller Regel wird der Administrator zudem auch auf ein Werkzeug zum Visualisieren der Alarme setzen, im vorliegenden Text kommt dafür Alerta zum Einsatz. Hinzu gesellt sich unter Umständen das Push-Gateway. Dieses dient den Systemen als Anlaufstelle, die sich nicht mit einem Exporter versorgen lassen, um ihre Metrikdaten direkt von Prometheus abholen zu lassen. Das Push-Gateway spielt dabei den Mittler. Es empfängt von diesen Systemen die Daten und bietet eine Schnittstelle, über die sie sich abrufen lassen (siehe Abbildung 1).
Auf der Clientseite ist das Szenario etwas weniger komplex. Dort laufen die Exporter, die die Metrikdaten sammeln und sie Prometheus per API verfügbar machen.
Wer Prometheus erst mal im kleinen Maßstab testen möchte, braucht nicht mehr als eine virtuelle Maschine. Diese sollte allerdings etwas Dampf unter der Haube haben, weil sie einerseits Metrikdaten selbst liefert und andererseits Prometheus betreibt, um diese zu speichern und auch an Grafana zu übergeben. Sonderlich realitätsnah ist dieses Setup aber nicht, und deshalb geht dieser Artikel von einem anderen Szenario aus. Das Ziel ist es, ein kleines Setup aus 200 Knoten zu überwachen. Ob das Monitoring von Anfang an Teil der Planung ist, ist übrigens nicht von Belang. Die Serverkomponenten lassen sich ohnehin jederzeit auf einem neuen System installieren, und weil die meisten Exporter für die Zielsysteme in Go verfasst sind, ist auch deren autarke Installation im Nachhinein kein Problem.
Für ein produktives Setup sollten wenigstens zwei Server zur Verfügung stehen: einer, auf dem Prometheus sowie gegebenenfalls das Push-Gateway läuft, sowie einer für die Frontend-Komponenten – Grafana, den Alertmanager und gegebenenfalls Alerta. Die Aufteilung dieser Art erleichtert das Skalieren in die Breite später erheblich. Sowohl Grafana als auch der Alertmanager lässt sich an fast beliebig viele Instanzen von Prometheus anbinden. Wer aus Scale-out-Gründen also diverse Prometheus-Instanzen in seinem Setup hat, verliert trotzdem nicht die Vorteile eines „Single Point of Administration“. Möchte man sein Setup redundant auslegen, braucht man jedoch die doppelte Menge an Hardware, um Fehlerunanfälligkeit zu erreichen.
SSD für Storage, sonst Mittelklasse
Top-Notch-Hardware muss es nicht unbedingt sein, allerdings empfiehlt sich schneller Blockspeicher. SSDs beschleunigen das Setup spürbar und verkürzen die Zeiten, die Prometheus für eine Antwort auf Anfragen benötigt. Weil sich Prometheus nur bedingt für Long-Term-Trending eignet, sollte eine handelsübliche SSD mit einigen GByte – abhängig von der Menge der überwachten Systeme – genügen. Wer ein paar ausrangierte Server hat, kann diese mit SSDs bestücken und als Basis verwenden.
Ist die Hardware organisiert, stellt sich die erste Frage: Welche Distribution soll als Unterbau dienen? Die gute Nachricht ist: Die relevanten Komponenten laufen in Form von Docker-Containern. Weil Docker für alle großen Distributionen zur Verfügung steht, hat der Administrator im Hinblick auf die Prometheus-Server letztlich freie Wahl. Im Folgenden geht der Artikel davon aus, dass auf den beiden Maschinen für die Prometheus-Komponenten CentOS 7 samt Docker in der Community-Edition zur Verfügung steht.