

Structured Streaming mit Apache Spark
Schöner strömen
Immer mehr Anwendungen aus Industrie und Wissenschaft benötigen Daten in Echtzeit. Das Apache-Projekt Spark als vielseitiges und quelloffenes Verarbeitungs-Framework ist für die Aufbereitung solcher gestreamten Daten prädestiniert.
Die Düsentriebwerke von Pratt & Whitney, die unter anderem im A320neo verbaut werden, produzieren nicht nur einen starken Luft-, sondern auch einen ebenso beeindruckenden Datenstrom von ca. 10 GByte/s oder 36 TByte/h (siehe ix.de/ix1809134). 5000 Sensoren erfassen permanent Informationen über das Triebwerk und seine Umgebung und helfen unter anderem dabei, den Verbrauch in Echtzeit zu optimieren. Insofern ist ein Düsentriebwerk ein anschauliches, wenn auch vielleicht ungewöhnliches Beispiel für Data Streaming.
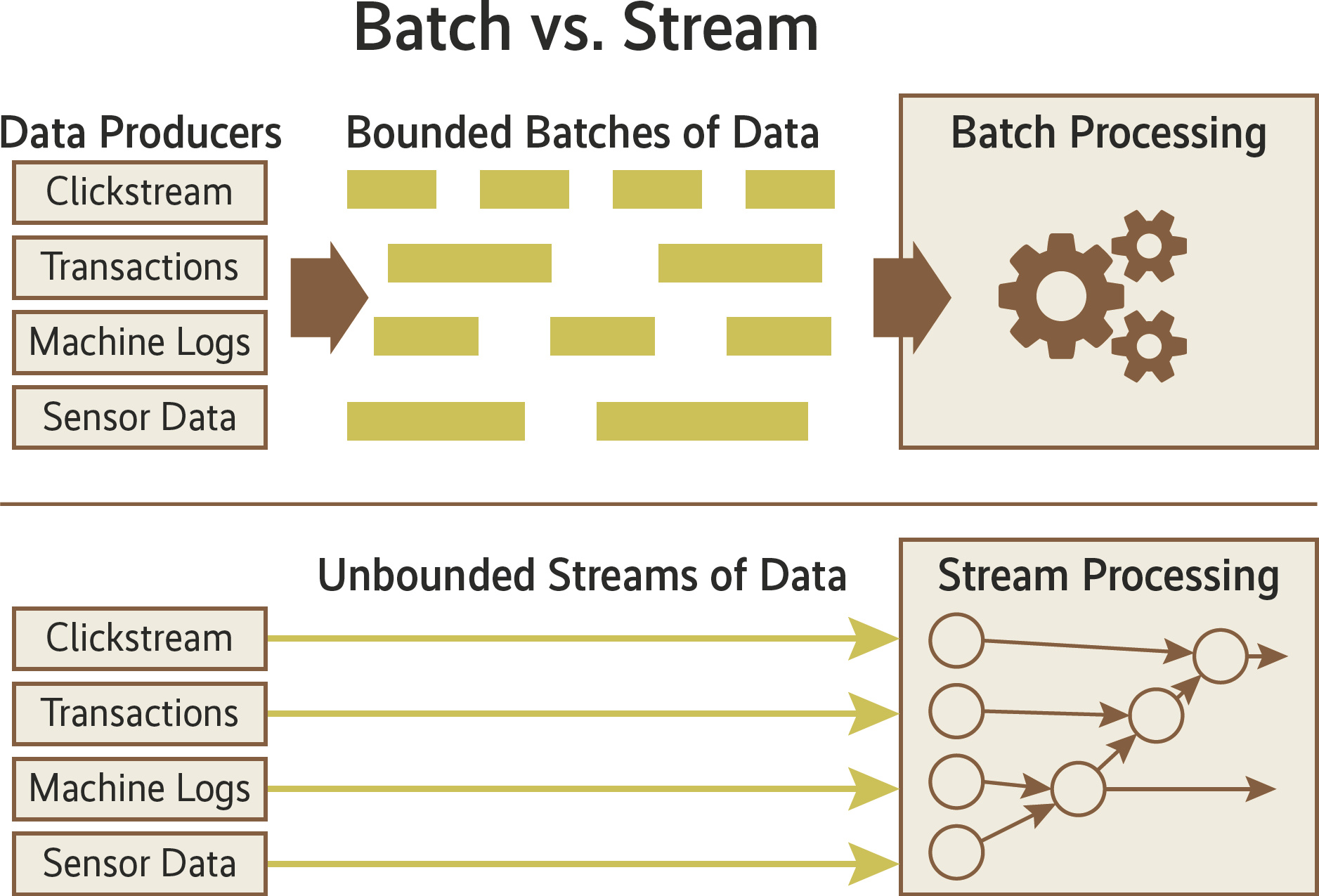
Als Data Streaming bezeichnet man die fortlaufende Verarbeitung eines kontinuierlich erzeugten Stroms von Nachrichten, Ereignissen, Transaktionen oder ganz allgemein Daten. Im Gegensatz zur Batch-Verarbeitung, bei der Daten im Quellsystem über längere Zeit gesammelt und dann als Stapel (Batch) verarbeitet werden, steht beim Streaming die zeitnahe Verarbeitung im Vordergrund. Es geht also um Realtime- oder besser: Near-Realtime-Anwendungen. Die Verarbeitungslatenz – die Zeit von der Erfassung der Daten bis zu deren Verarbeitung und Weiterleitung – liegt bei Streaming-Systemen im Sekunden- und Millisekundenbereich. Typische Anwendungsfälle in der Industrie finden sich insbesondere bei der Steuerung und Überwachung zeitkritischer Systeme und Prozesse:
– Systeme zur Erkennung von Kreditkartenmissbrauch zum Beispiel sollen bestimmte Nutzungsmuster in Echtzeit identifizieren und die Karte gegebenenfalls automatisch sperren.
– Fertigungssteuerungssysteme sollen den Status von Maschinen überwachen und sofort reagieren, wenn bestimmte Schwellwerte überschritten werden.
– Empfehlungssysteme sollen gezielt Werbung in Abhängigkeit von konkreten Nutzeraktionen, vom Standort oder sonstigem Kontext generieren.
– Live-Dashboards sollen jederzeit den Zustand der Systeme, zum Beispiel im Rechenzentrum, visualisieren und bei Problemen Benachrichtigungen verschicken.
Für den Umgang mit Daten gibt es heutzutage sehr leistungsfähige Software-Frameworks. Allein unter dem Dach der Apache Foundation finden sich über zwanzig Projekte, die sich mit Data Streaming befassen. Im Kern lassen sich zwei Arten von Streaming-Systemen unterscheiden:
– Message Broker beziehungsweise Message Queues sind für die zuverlässige Zustellung von Nachrichten von Quell- an Zielsysteme verantwortlich, stellen aber keine Funktionen zur Verarbeitung der Daten bereit. Im Big-Data-Umfeld kommt häufig Apache Kafka zum Einsatz. Weitere Vertreter dieser Gattung sind Amazon Kinesis, RabbitMQ und ActiveMQ.
– Stream Processing Engines oder Stream Processors wie Spark Streaming erlauben neben der Weiterleitung von Nachrichten auch deren Verarbeitung einschließlich komplexer, nachrichtenübergreifender Operationen wie Aggregationen oder Joins. Apache Flink, Apache Storm und Kafka Streams fallen ebenfalls in diese Kategorie.
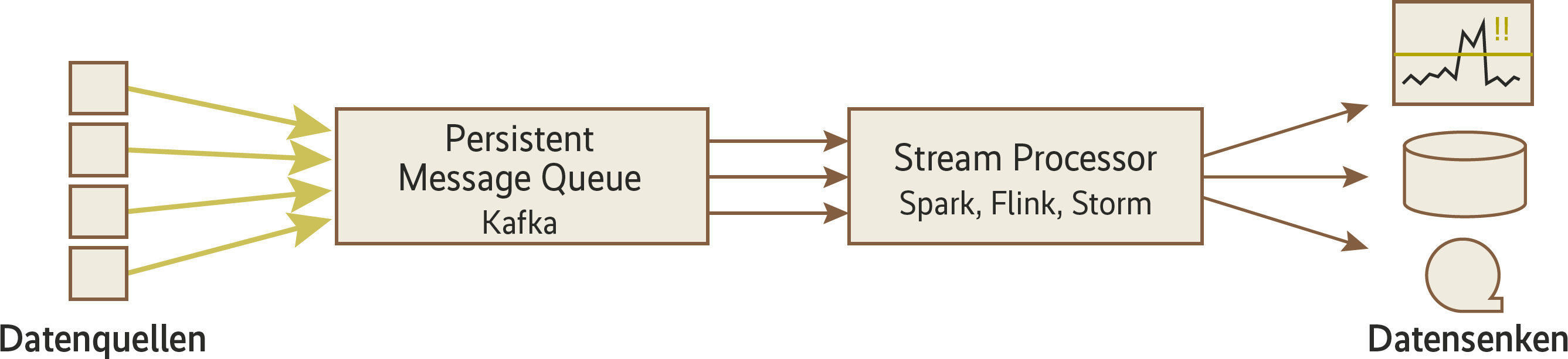
In der Praxis ist die Kombination von Kafka mit entweder Spark Streaming oder Flink häufig anzutreffen, denn Kafka ermöglicht nicht nur die Entkopplung von Streaming-System und Datenquellen, sondern erlaubt durch seine persistente Datenhaltung auch die Pufferung und Mehrfachverarbeitung der Daten. Das ist insbesondere im Fehlerfall wichtig, denn die Quellsysteme produzieren Nachrichten munter weiter, auch wenn das Streaming-System mal geplant oder ungeplant stillsteht.
Verteiltes Streamen im Cluster
Sollen Tausende von Nachrichten pro Sekunde verarbeitet werden, geht das nur mit einem verteilten System. In diesem Fall sind mehrere Knoten in einem Cluster für die Verarbeitung zuständig, wobei jeder Knoten einen bestimmten Teil der Nachrichten verarbeitet. Damit im Fehlerfall keine Nachrichten verloren gehen, müssen sie redundant auf mehrere Knoten repliziert werden. Diese verteilte Architektur führt zu einigen technischen Herausforderungen.
So sollte jede Nachricht genau einmal („exactly once“) verarbeitet werden. Bei einem Systemausfall kann aber nicht ohne Weiteres gesagt werden, ob eine Nachricht schon verarbeitet wurde oder nicht. Ist ein Nachrichtenverlust nicht akzeptabel, müssen die Streaming-Daten und der aktuelle Verarbeitungsstatus in irgendeiner Form persistiert werden, um ein Wiederaufsetzen zu ermöglichen. Dabei kann es unter Umständen zur Mehrfachverarbeitung kommen. Einfachere Forderungen sind daher „at most once“ (erlaubt Nachrichtenverlust) oder „at least once“ (erlaubt Mehrfachverarbeitung).