

Machine-Learning-Projekte umsetzen mit dem DevOps-Ansatz
Gezwitscher entziffern
Mit Machine-Learning-Algorithmen können Unternehmen Erkenntnisse aus großen Datensätzen gewinnen. Mit DevOps-Methoden lässt sich der Weg vom Erstellen des Datensatzes über das Training eines Machine-Learning-Modells bis hin zur produktiven Auslieferung standardisieren.
Beim Coding Da Vinci Ost Hackathon im Frühjahr 2018 haben wir, eine Gruppe von vier Studierenden aus dem Raum Leipzig, uns das Ziel gesetzt, mit Open-Source-Werkzeugen eine ML-basierte, benutzerzentrierte Applikation zu entwickeln. Der Open-Source-Gedanke war entscheidend, denn im Vordergrund des Hackathons stand die Nutzung öffentlich zugänglicher Kulturdaten. Eine weitestgehend modulare Architektur sollte es zudem möglich machen, Teilkomponenten auch für andere Anwendungsfälle zu nutzen.
Ausgehend von einem aus Vogelstimmen bestehenden Datensatz des Naturkundemuseums Berlin (MFN) wollten wir einen Klassifizierer entwickeln, der anhand von Audiodateien eine große Vielfalt an Vögeln identifizieren kann. Die Herausforderung: nur 90 Tage Zeit, ein geeignetes Machine-Learning-Modell zu trainieren sowie parallel eine Smartphone-App und ein Server-Backend zu entwickeln.
Von auditiv zu visuell: Klang als Bild
Prinzipiell geht es beim maschinellen Lernen darum, ein heuristisches Modell zu entwerfen, das versucht, Muster in einer großen Menge an Eingangs- oder Trainingsdaten zu erkennen und die Methoden zur Erkennung dieser Muster zu internalisieren. Somit ist es dann nach dem eigentlichen Training des Modells möglich, ähnliche Muster auch in unbekannten, aber gleich strukturierten Daten zu identifizieren.
Bilderkennung ist ein beliebter Anwendungsfall für maschinelles Lernen. In den meisten Fällen kommt hier das sogenannte Supervised Learning zum Einsatz, bei dem das Modell mit einer großen Menge bereits klassifizierter Ausgangsdaten gefüttert wird. Ein auf Tierfotos trainiertes Modell versucht zum Beispiel, gewisse Merkmale herauszufiltern, um zu bestimmen, um welches Tier es sich auf einem Bild handelt. In diesem Bereich gibt es viele leistungsfähige, vortrainierte Modelle wie VGG, ResNet oder ImageNet. Mit eigenen Daten lassen sie sich, sofern diese in ihrer Struktur mit denen des Modells übereinstimmen, an die eigenen Bedürfnisse anpassen. Je nach Größe des Modells und der Menge an Eingangsdaten kann das Training von mehreren Stunden bis hin zu Tagen oder Wochen dauern. Um auf die gewünschten Ergebnisse zu kommen, ist systematisches Ausprobieren gefragt.
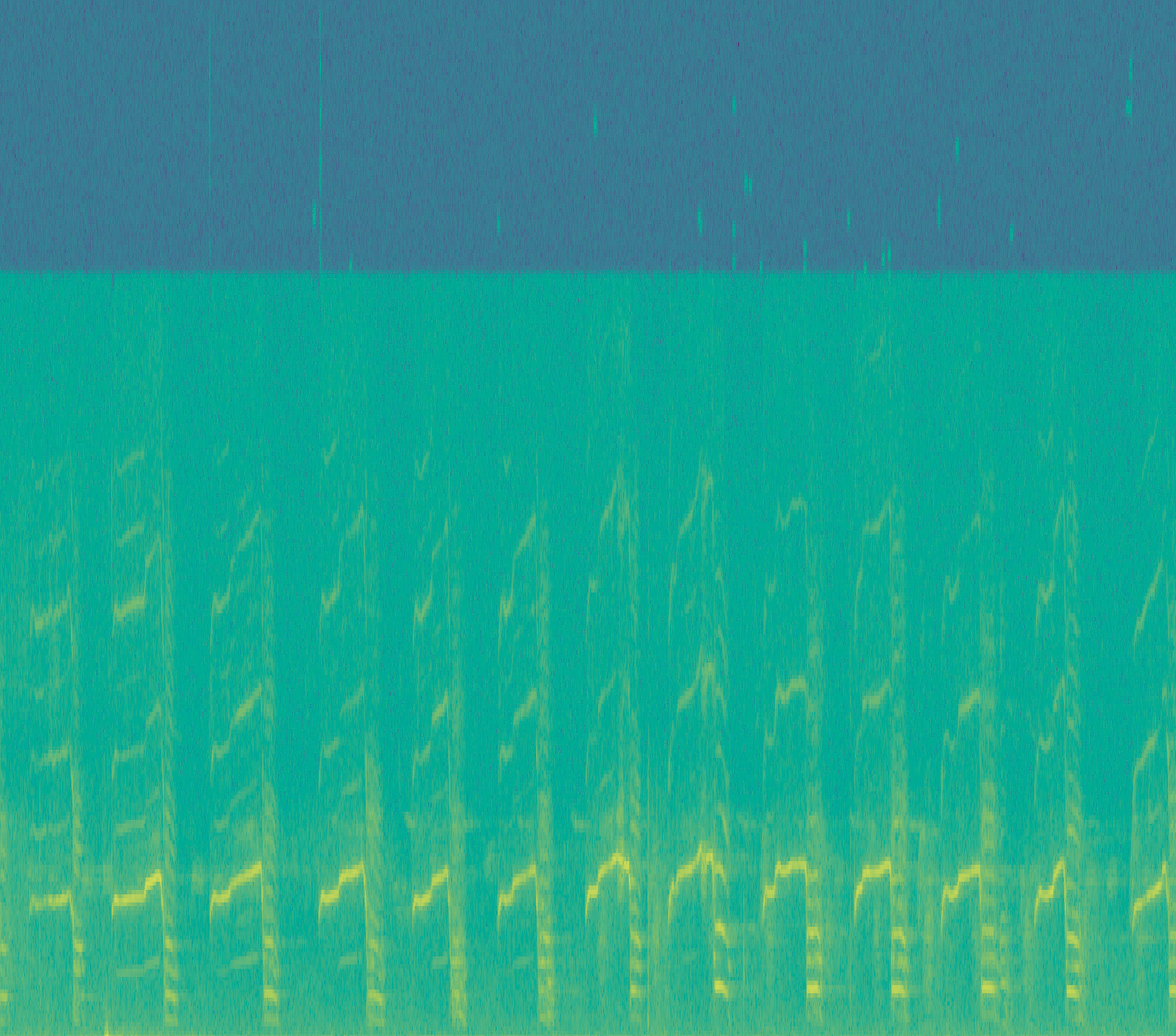
VGGish ist ein 2017 zur Audio-Event-Erkennung von mehreren Millionen YouTube-Videofragmenten entworfenes Machine-Learning-Modell von Google. Dabei werden klassische Bilderkennungsalgorithmen auf vorher in Frequenzspektrogramme umgewandelte Audiodateien angewandt. Das VGGish-Modell ist zum größten Teil schon vordefiniert und erlaubt es, mit wenigen Modifikationen einen Klassifizierer für eigene Audioklassen, zum Beispiel Vogelstimmen, zu entwickeln. Diese Übertragung gewonnener Erkenntnisse auf ein vergleichbares Problem bezeichnet man auch als Transfer Learning.
Hartes Training
In Projekten mit straffen Deadlines, die ein möglichst effizientes Arbeiten erfordern, empfiehlt sich der DevOps-Ansatz. Hierbei arbeiten alle Parteien bei Backend-, Infrastruktur- und Forschungsaufgaben eng zusammen (kurze Feedback-Loops) und die Teams setzen auf skriptbasierte Automatisierung und reproduzierbare Builds mittels Infrastructure as Code. Die vom MFN über das Tierstimmenarchiv bereitgestellten Daten des Vogelstimmenprojekts galt es zunächst über Europeana, eine europäische Meta-API für Kulturgüter, mithilfe eines selbst in Golang geschriebenen API-Clients zu beziehen.
Sind weitere Aktionen erforderlich, um die Ausgangsdaten so vorzubereiten, dass sie eine gute Basis für das anschließende Modelltraining bilden, lassen sich auch diese in vielen Fällen per Skript automatisieren. Oft wird der vorliegende Datenbestand zu viele oder nicht relevante Klassen (Labels) enthalten. Sie erschweren das Erstellen eines aussagefähigen Modells und müssen vor dem eigentlichen Training entfernt oder angepasst werden. Häufiger noch fehlen benötigte Zusatzinformationen für die spätere Abfrage des Modells. Diese lassen sich per API einbinden. Für das Vogelprojekt leisteten zum Beispiel Wikipedia und die offene Vogelstimmendatenbank xeno-canto.org gute Dienste.
Die in jedem Schritt gesammelten Metadaten laufen in einer JSON-Datei zusammen, die am Ende des Datenaufbereitungsprozesses mithilfe der Python-Bibliothek Pandas bereinigt und normalisiert werden kann. Das Ergebnis dieser Mühen bildet letztendlich die Grundlage für die Datenbank der Anwendung.